GPT3、ChatGPT 和 BARD 等大型語言模型 (LLM) 如今風靡一時。每個人都對這些工具對社會的好壞以及它們對 AI 的未來意味著什麼有自己的看法。谷歌因其新模型 BARD 錯了一個複雜的問題(輕微)而受到了很多批評。當被問到“我可以告訴我 9 歲的孩子關於詹姆斯·韋伯太空望遠鏡的哪些新發現?” – 聊天機器人提供了三個答案,其中 2 個正確,1 個錯誤。錯誤的是第一張“系外行星”照片是由 JWST 拍攝的,這是不正確的。所以基本上,該模型在其知識庫中存儲了一個不正確的事實。為了使大型語言模型有效,我們需要一種方法來更新這些事實或用新知識擴充事實。
讓我們首先看看事實是如何存儲在大型語言模型 (LLM) 中的。大型語言模型不像數據庫或文件那樣存儲傳統意義上的信息和事實。相反,他們接受了大量文本數據的訓練,並學習了這些數據中的模式和關係。這使他們能夠對問題做出類似人類的回答,但他們沒有特定的存儲位置來存儲他們學到的信息。在回答問題時,模型會使用其訓練來根據收到的輸入生成響應。語言模型所擁有的信息和知識是它在其訓練數據中學習到的模式的結果,而不是它被顯式存儲在模型內存中的結果。大多數現代 LLM 所基於的 Transformers 架構有一個內部事實編碼,用於回答提示中提出的問題。
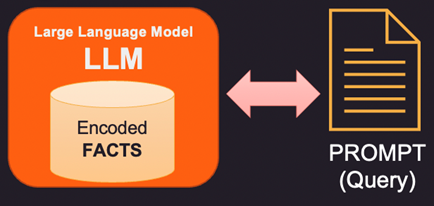
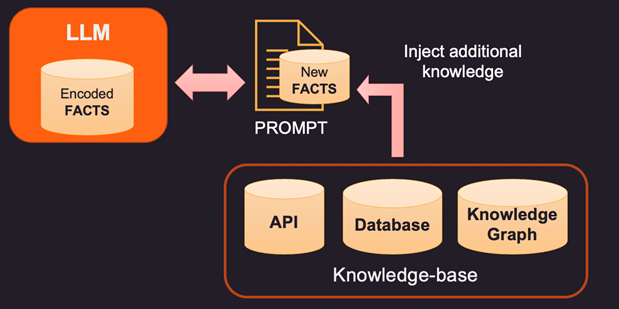
因此,如果 LLM 內部存儲器中的事實錯誤或陳舊,則需要提供新信息通過提示。提示是發送給 LLM 的文本,其中包含查詢和支持證據,這些證據可以是一些新的或更正的事實。這裡有 3 種方法來解決這個問題。
1.糾正 LLM 編碼事實的一種方法是使用外部知識庫提供與上下文相關的新事實。該知識庫可能是用於獲取相關信息的 API 調用或對 SQL、No-SQL 或 Vector 數據庫的查找。可以從存儲數據實體及其之間關係的知識圖譜中提取更高級的知識。根據用戶查詢的信息,可以檢索相關上下文信息並將其作為附加事實提供給 LLM。這些事實也可以格式化為看起來像訓練示例以改進學習過程。例如,您可以為模型傳遞一堆問題答案對,以學習如何提供答案。
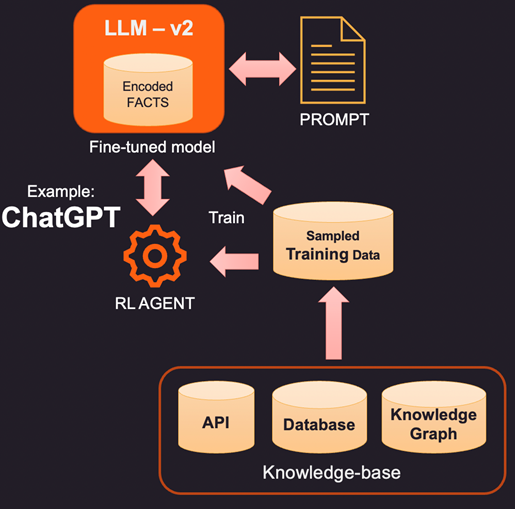
2.增強 LLM 的一種更具創新性(也更昂貴)的方法是使用訓練數據進行實際微調。因此,我們不是查詢知識庫以添加特定事實,而是通過對知識庫進行採樣來構建訓練數據集。使用諸如微調之類的監督學習技術,我們可以創建一個新版本的 LLM,該版本是根據這些額外知識進行訓練的。這個過程通常很昂貴,在 OpenAI 中構建和維護一個微調模型可能要花費幾千美元。當然,隨著時間的推移,成本會越來越低。
3.另一種選擇是使用強化學習 (RL) 等方法來訓練具有人類反饋的代理,並學習如何回答問題的策略。這種方法在構建擅長特定任務的較小足跡模型方面非常有效。例如,OpenAI 發布的著名 ChatGPT 是在監督學習和 RL 與人類反饋相結合的情況下進行訓練的。
總而言之,這是一個高度發展的空間,每個大公司都希望進入並展示他們的差異化。我們很快就會在零售、醫療保健和銀行業等大多數領域看到主要的 LLM 工具,它們可以像人類一樣理解語言的細微差別。這些與企業數據集成的 LLM 支持工具可以簡化訪問並在正確的時間向正確的人提供正確的數據。