深度學習和強化學習是人工智能中最流行的兩個子集。 AI 市場在 2022 年約為 1200 億美元,並以超過 38% 的令人難以置信的複合年增長率增長。隨著人工智能的發展,這兩種方法(RL 和 DL)已被用於解決許多問題,包括圖像識別、機器翻譯和復雜系統的決策制定。我們將以一種易於理解的方式探討它們如何工作以及它們的應用、局限性和差異。
什麼是深度學習 (DL) ?
深度學習是機器學習的一個子集,我們在其中使用神經網絡來識別給定數據中的模式,以便對看不見的數據進行預測建模。數據可以是表格、文本、圖像或語音。
深度學習出現於 1950 年代,當時弗蘭克·羅森布拉特 (Frank Rosenblatt) 於 1958 年撰寫了一篇關於感知器的研究論文。感知器是第一個神經網絡架構師可以訓練執行線性監督學習任務的結構。隨著時間的推移,該領域的研究、海量數據的可用性以及廣泛的計算資源進一步推動了深度學習領域。
深度學習如何工作?
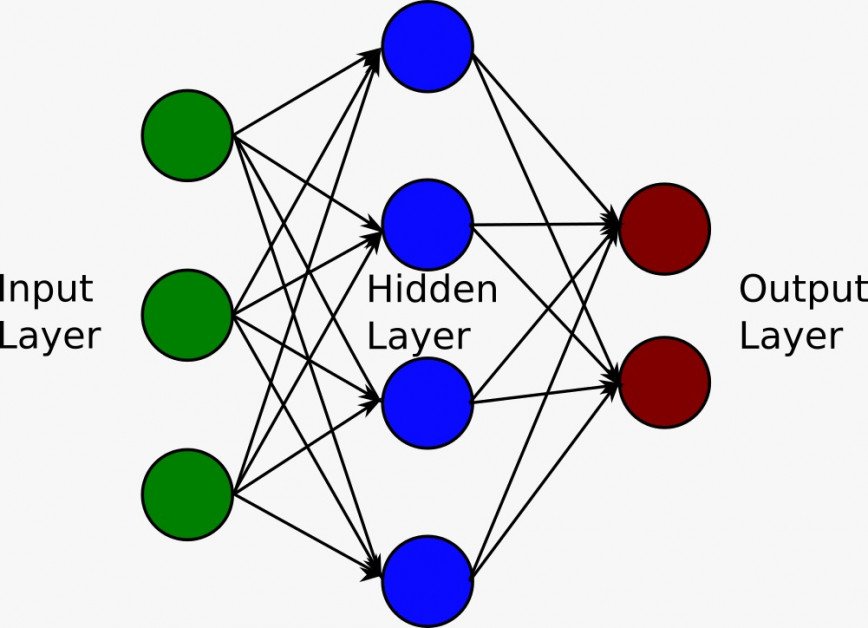
神經網絡是深度學習的基石。人腦啟發了神經網絡;它包含傳輸信息的節點(神經元)。神經網絡分為三層:
輸入層隱藏層輸出層。
輸入層接收用戶提供的數據並將其傳遞給隱藏層。隱藏層對數據進行非線性變換,輸出層顯示結果。使用損失函數計算輸出層的預測值與實際值之間的誤差。該過程不斷迭代直到損失最小化。
a>
深度學習架構的類型
神經網絡架構有多種類型,例如:
神經網絡架構的使用取決於正在考慮的問題類型。
深度學習的應用
深度學習在許多行業都有應用。
在醫療保健領域,基於計算機視覺的方法使用卷積神經網絡可以是用於分析醫學圖像,例如 CT 和 MRI 掃描。在金融領域,它可以預測股票價格和檢測欺詐活動。自然語言處理中的深度學習方法用於機器翻譯、情感分析等。
深度學習的局限性學習
雖然深度學習已經達到了境界許多行業的藝術成果,它都有其局限性,如下所示:
海量數據:深度學習需要大量標記數據進行訓練。缺少標記數據會導致結果不佳。耗時:在數據集上進行訓練可能需要數小時,有時甚至數天。深度學習需要進行大量實驗才能達到所需的基准或取得切實的結果,而缺乏快速迭代會減慢該過程。計算資源:深度學習需要 GPU 和 TPU 等計算資源進行訓練。深度學習模型在訓練後會佔用大量空間,這在部署過程中可能會成為一個問題。
什麼是強化學習 (RL)?
另一方面,強化學習是人工智能的子集代理對其環境執行操作。 “學習”是通過在智能體經歷所需行為時獎勵它並在其他情況下對其進行懲罰來實現的。憑藉經驗,代理學習最佳策略以最大化獎勵。
從歷史上看,強化學習在 1950 年代和 1960 年代受到關注,因為決策算法是為複雜系統開發的。因此,該領域的研究催生了 Q-Learning、SARSA 和 actor-critic 等新算法,進一步推進了該領域的實用性。
強化學習的應用
強化學習學習在所有主要行業都有顯著的應用。
機器人技術是強化學習中最著名的應用之一。使用強化學習方法,我們允許機器人從環境中學習並執行所需的任務。強化學習用於開發國際象棋和圍棋等遊戲的引擎。 AlphaGo(圍棋引擎)和AlphaZero(國際象棋引擎)是使用強化學習開發的。在金融領域,強化學習可以幫助進行有利可圖的交易。
強化學習的局限性
海量數據:強化學習需要大量數據和經驗來學習最優策略。獎勵利用:在探索狀態、形成最優策略和利用獲得的知識以增加獎勵之間保持平衡很重要。如果探索低於標準,智能體將無法達到最佳結果。安全性:如果獎勵系統未設計和適當約束,強化學習會引發安全問題。
顯著差異
簡而言之,強化學習之間的顯著差異強化學習和深度學習如下:
深度強化學習——結合
深度強化學習作為一種結合了強化和深度學習方法的新技術而出現。最新的國際象棋引擎,例如 AlphaZero,就是深度強化學習的一個例子。在 AlphaZero 中,深度神經網絡使用數學函數讓智能體學習與自己下棋。
每年,市場上的大玩家都會開發新的研究和產品。深度學習和強化學習有望以前沿的方法和產品震驚我們。