有許多排序算法可用於對數據集進行排序。通常,此數據顯示在列表或數組中。在這些算法中,選擇排序算法是最容易理解和實現的算法之一。在本文中,我們將解釋選擇排序背後的理論、它是如何實現的,以及使用該算法的最佳實踐。
什麼是選擇排序?
選擇排序是基於比較的排序算法。它的工作原理是將數組分成兩部分——已排序和未排序。選擇具有最小值的元素,並將其放置在已排序子數組的索引 0 處。也可以先選擇最大的元素,具體取決於您希望列表按升序還是降序排列。這是一個迭代過程,意味著重複該方法,直到所有元素都按正確位置放入已排序數組中。如您所料,每次迭代時,已排序的子數組大小都會增加一個元素,而未排序的數組大小會減少一個元素。
 您可以使用多種編程語言實現選擇排序,包括 C、C++、C#、PHP、Java、Javascript 和Python。
您可以使用多種編程語言實現選擇排序,包括 C、C++、C#、PHP、Java、Javascript 和Python。
選擇排序背後的算法
選擇排序背後的算法相當簡單,遵循以下步驟:
 找到未排序數組中的最小元素並與索引 0 中的第一個元素交換。然後未排序數組遍歷以找到新的最小元素。如果發現任何元素小於索引 0 中的元素,則交換元素。找到未排序數組中的下一個最小元素,並按照先前的約束將其添加到已排序的子數組中.重複這個過程,直到整個數組排序完畢。
找到未排序數組中的最小元素並與索引 0 中的第一個元素交換。然後未排序數組遍歷以找到新的最小元素。如果發現任何元素小於索引 0 中的元素,則交換元素。找到未排序數組中的下一個最小元素,並按照先前的約束將其添加到已排序的子數組中.重複這個過程,直到整個數組排序完畢。
選擇排序的工作原理
現在我們已經介紹了選擇排序的工作原理,是時候用一個例子來說明了。
如果我們考慮數組 [72, 61, 59, 47, 21]:
該過程的第一步或迭代涉及從索引 0 到索引 4 遍歷整個數組(請記住第一個索引設置為 0,而不是 1)。
找到的最小元素是 21,所以它與第一個元素 72 交換。如下圖所示。
[21, 61, 59, 47, 72]
其中 green=已排序元素
對於第二遍,我們發現 47 是第二小的值。然後將其與 61 交換。
[21, 47, 59, 61, 72]
第三遍檢測到 59 是第三個元素,它已經就位。因此,不會發生交換。
[21, 47, 59, 61, 72]
第四遍發現 61 是第四個元素,同樣,它已經存在。
[21, 47, 59, 61, 72]
第五遍也是最後一遍的結果大致相同。 72 是第五小或最大的元素,並且位於正確的位置。現在,數組已經完全按照升序排序了。
[21, 47, 59, 61, 72]
選擇排序的實現
我們可以實現使用各種編程語言進行選擇排序,包括最常見的 C、C++、C#、PHP、Java、Javascript 和 Python。為了說明,我們將使用 Python。使用Python的代碼如下:
def SSort(arr, size): for step in range(size): min_idx=step for i in range(step + 1, size): if arr[i] arr [min_idx]: min_idx=i (arr[step], arr[min_idx])=(arr[min_idx], arr[step]) 數據=[-7, 39, 0, 14, 7] size=len(data) SSort(data, size) print(‘Ascending Sorted Array:’) print(data)
代碼解釋
在這個階段,對所用代碼的解釋會很有幫助。首先,我們將函數“SSort”定義為具有指定大小的數組的函數。
“for”循環指示循環將開始,該循環將迭代“大小”的範圍,這意味著數組的長度。 “step”變量表示每次迭代將取值 0、1、2……直到 size-1。
下一行顯示“step”的初始值等於變量“ min_idx”。這是一種跟踪未排序數組中最小元素位置的方法。
下一個“for”循環指定一個將迭代未排序數組的循環,從“step + 1”開始.這是因為“step”元素已經放在排序的數組中。每次迭代中的“i”變量將等效於 step + 1、step + 2 等等,直到大小為 – 1。
檢查當前元素是否位於“i”的“if”語句小於當前最小元素。如果發現是這種情況,則更新最小元素以反映這一點。
最後,這一相當複雜的行具有簡單的含義。前一個循環完成後,最小未排序元素將與未排序數組中的第一個元素交換。這有效地將元素添加到排序數組的末尾。
底部的代碼簡單地指定了我們正在處理的數組,長度為“size”,並調用選擇排序來處理這個大批。然後輸出標題為“升序排序數組”。
無論何時使用 Python,使用正確的縮進來指定單獨的操作都是至關重要的。否則,您將收到一條錯誤消息並且計算不會運行。
代碼的外觀
查看下面的屏幕截圖,了解此代碼在中實現時的外觀Python.
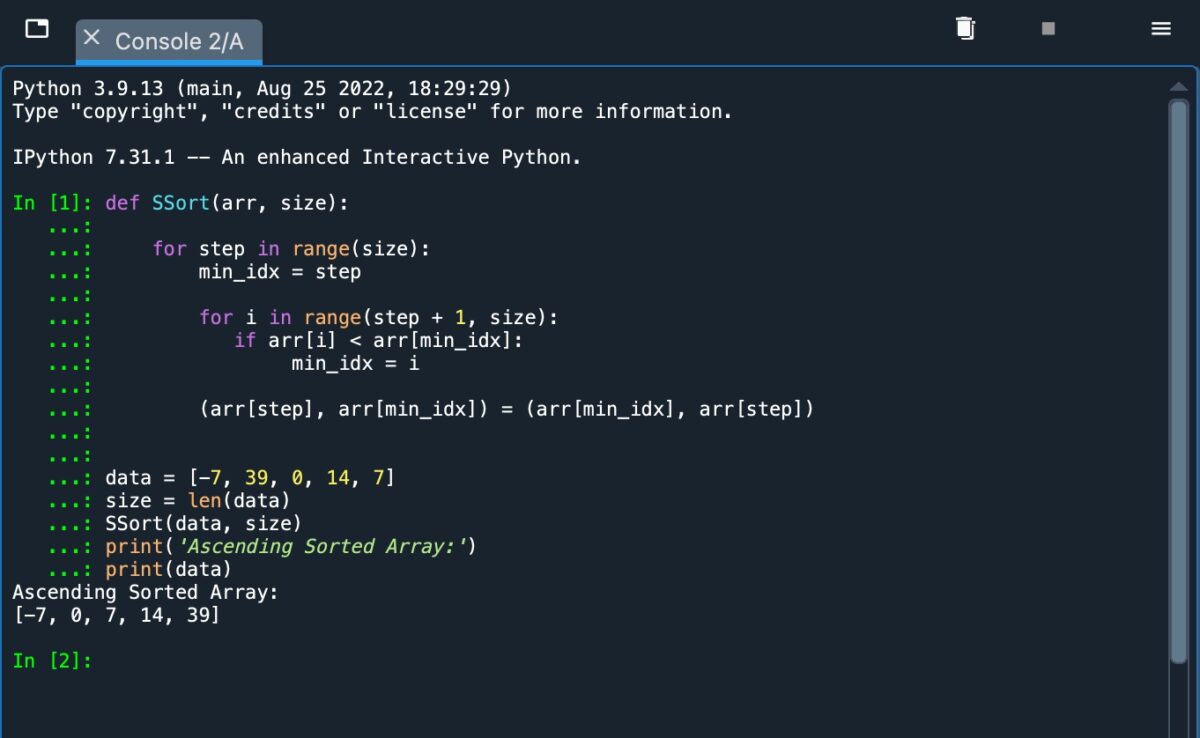 使用時Python,您必須使用正確的縮進來指定單獨的操作。
使用時Python,您必須使用正確的縮進來指定單獨的操作。
©”TNGD”.com
插入排序的最佳和最差用例
雖然插入排序很有用對於許多目的,就像任何算法一樣,它有最好和最壞的情況。這主要歸結為時間和空間複雜度。
插入排序的時間複雜度
每種情況下的時間複雜度可以在下表中描述:
就像對於任何算法,選擇排序都有其自身的時間和空間複雜度。這基本上是指複雜性或執行速度在各種情況下如何變化。時間複雜度可以總結如下表:
最佳情況是指數組排序時,平均情況是指數組混亂,最壞情況是指數組按升序或降序排列,而您想要相反的順序。換句話說,它們指的是完成該過程需要多少次迭代,最壞的情況需要最大迭代次數。
對於這種情況,選擇排序的時間複雜度在每種情況下都是相同的案件。這是因為無論數組如何排序,該算法總是執行相同數量的比較和交換。因此,複雜度為O(n2),也稱為二次時間。就排序算法而言,這是該算法效率不高的一個主要原因,但這也意味著效率不依賴於輸入的分佈。
選擇排序的空間複雜度
空間複雜度是指計算需要多少內存。在選擇排序的情況下,這等於 O(1)。這意味著需要恆定數量的內存,與輸入大小無關。唯一存儲的臨時變量是“min_idx”,它不會隨著輸入大小的增加而改變。
總結
選擇排序是一種相對簡單但相當低效的元素排序算法在給定的輸入中。它主要適用於非常小的數據集,並且可以使用多種編程語言來實現。選擇排序的工作原理是將數組拆分為兩個子數組,已排序和未排序。然後該過程遍歷數組以找到最小元素,並將該元素移動到索引 0。重複該過程,找到第二和第三小的元素,依此類推,並將它們交換到正確的索引位置。這一直持續到對整個數組進行排序。
Up Next…
選擇排序算法解釋,示例 FAQs(常見問題)
什麼什麼是選擇排序?
選擇排序是一種簡單的排序算法,它將元素數組按升序或降序排序。它通過遍歷數組找到最小元素,並將其與排序子數組中索引 0 中的元素交換來實現。然後再次遍歷未排序的子數組,找到最小元素並將其交換到正確的位置。該算法重複此過程,直到對整個數組進行排序。選擇排序是一種簡單的排序算法,其工作原理是從數組的未排序部分中重複查找最小元素,並將其放在數組已排序部分的開頭。該算法在給定數組中維護兩個子數組。
選擇排序的優點是什麼?
選擇排序是一種非常容易理解和實現的算法, 並且對於非常小的數據集已經足夠了。
選擇排序有什麼缺點?
因為它不是很有效,所以選擇排序在處理大數據集。它的效率不依賴於輸入分佈,但這也意味著它在所有情況下都是低效的,無論初始數組已經如何排序。它也不是一個穩定的算法,這意味著可能無法保留相等元素的相對順序。總而言之,在大多數情況下都有更好的排序算法,可以更好地適應有問題的輸入。
什麼情況最適合使用選擇排序?
選擇排序最適用於輸入規模較小,並且您想要一種簡單且相對高效的解決方案。由於空間複雜度為 O(1),如果您需要關注內存使用情況,選擇排序具有優勢。因為它總是執行相同數量的迭代,所以在對已經部分排序的數組進行排序時,它可能比其他一些算法表現更好,因為花費相同的時間比花費更長的時間更好。如果不需要穩定的排序算法,選擇排序是一個可行的選擇。
選擇排序的時間複雜度是多少?
時間選擇排序的複雜度是二次的,表示為O(n2)。
選擇排序的空間複雜度是多少?
空間複雜度是O( 1).這意味著每次迭代都使用恆定數量的內存,因為只需要存儲一個臨時變量。雖然該算法可能效率低下,但空間複雜性意味著它在內存使用受限的情況下具有優勢。
選擇排序有哪些替代方案?
許多其他排序算法在大多數用例中會更有效。這些包括歸併排序、快速排序和堆排序。這些算法往往更具適應性,並且具有更好的時間複雜度。在這些備選方案中,合併排序是唯一穩定的算法,因此在需要保留相等元素的相對順序的情況下是可行的。
選擇排序是穩定的算法嗎?
不,這不是一個穩定的算法。這意味著,在對數組進行排序時,等值元素在交換發生後可能不會按其原始順序保留。