© Oselote/Shutterstock.com
冒泡排序算法是簡單排序算法的一個例子。這種類型的算法按照您使用代碼解決的問題確定的特定順序排列字符、字符串或數字。
當您想按字母順序或數字順序排列項目時,排序通常很有用.排序算法是編程的重要組成部分,而冒泡排序由於其簡單性而受到學生的喜愛。但是,如果您需要快速性能,它不是最佳選擇。

如果如果您想詳細了解冒泡排序算法及其工作原理,那麼您來對地方了。今天的文章將分解冒泡排序算法的工作原理,並向您展示如何實現它。讓我們開始吧!
什麼是冒泡排序算法?
排序算法為您提供了一種在執行代碼時以邏輯方式呈現數據的方法。當您學習編程時,冒泡排序是您首先要學習的算法之一,因為它可以讓您從基礎層面直觀地了解排序算法的工作原理。
冒泡排序算法的獨特之處在於它只能比較相鄰的兩組數據。它遍歷整個數組、字典、列表或字符串並比較每個項目,然後根據您的要求對所有內容進行排序。
算法
在我們探索如何創建冒泡排序之前在您的代碼中,讓我們逐步了解它是如何工作的:
首先,我們將確定需要排序的數據集合。這可以是您打算以特定方式排列的數字、單詞或字母的集合。冒泡排序的一個常見功能是獲取數字列表並按它們的值從低到高或從高到低排序。算法從列表中的第一項開始,即索引 0 處的數據。它將該數據與索引 1 處的數據進行比較,以確定是否需要進行切換。如果進行了切換,我們將設置一個標誌,允許我們退出算法以使其更高效。接下來,它比較索引 1 到索引 2,它繼續遍歷列表,直到到達末尾。一旦算法經過一次,它就需要再次經歷這個過程,因為直到不需要進行任何切換,它才算完成。這通常是通過嵌套循環來完成的,嵌套循環對整個列表執行冒泡排序,直到有條件地對標誌進行操作,一旦我們完成了沒有更改的完整迭代就退出。一旦執行了這些嵌套循環,排序後的列表將按照預期的順序排列,以便您可以將其顯示在屏幕上或將其用於代碼中的進一步操作。 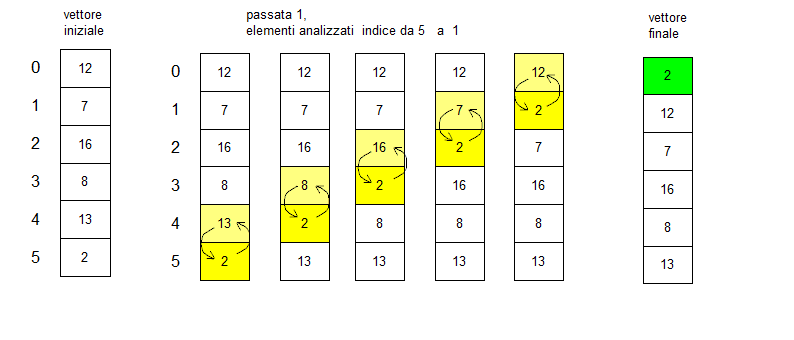 冒泡排序算法用圖表說明。
冒泡排序算法用圖表說明。
©Stefano furin – 自己的作品,CC BY-SA 4.0,https://commons.wikimedia.org/w/index.php?curid=37141358
冒泡排序算法的功能
既然我們已經介紹了冒泡排序算法的邏輯,讓我們更深入地研究一個示例。我們將採用亂序的數字列表,並讓冒泡排序將它們按升序排列。
為簡單起見,我們將使用包含四個數字的列表:
29, 15, 0,-5
冒泡排序要做的第一個計算是檢查索引 0 和索引 1 的值,正如我們上面討論的那樣。由於 29 大於 15,它們的位置將交換,給我們這個數字序列:
15, 29, 0,-5
接下來,算法比較 29 和 0。這是結果列表:
15, 0, 29,-5
第一次迭代的最後一次,算法比較 29 和-5,給我們這個列表:
15, 0,-5, 29
我們的列表不在我們需要的位置,下一次迭代將幫助我們對其進行排序。我們將看到列表以這種方式變化:
0, 15,-5, 29
0,-5, 15, 29
0,-5, 15, 29
0,-5, 15, 29
然後第三次迭代會給我們這樣的結果:
-5, 0, 15 , 29
-5, 0, 15, 29
-5, 0, 15, 29
-5, 0, 15, 29
>
現在,因為列表是完全排序的,我們需要一種方法來告訴循環停止執行。這是為了提高效率。為此,我們通常使用布爾變量和一些條件語句,以允許算法在未進行任何切換時跳出循環。
使用 For 循環實現冒泡排序算法
現在,讓我們將冒泡排序算法的一些代碼放入 Python 中,以更好地理解它作為一種排序方法的工作原理。以下是我們如何使用 for 循環實現它:
def bubbleSort (numArray, z): for a in range(z-1): swap=False for b in range (0, z-a-1): if numArray[b] > numArray[b+1]: swap=True numArray[b], numArray[b+1]=numArray[b+1], numArray[b] 如果不交換:返回 numArray numberArray=[82, 67 , 0,-500,-80, 99, 2] x=len(numberArray) print (“Sorted Array:”) print (bubbleSort(numberArray, x))
代碼解釋
讓我們逐步分解這段代碼,以便我們了解發生了什麼。
初始化數組
首先,我們需要用一組數字初始化我們的數組d 喜歡排序 (numberArray)。這些是故意以隨機順序初始化的,以演示冒泡排序算法的工作原理。接下來,我們初始化一個變量來存放數組 (x) 中的項目數。稍後我們將使用此變量來控制循環迭代的次數。
定義冒泡排序算法
將兩個值傳遞給算法,定義為 bubbleSort.第一個值是數組本身。然後我們也傳入數組的長度。在算法內部,它們分別被重新分配為 numArray 和 z。
我們用來執行冒泡排序的循環將迭代一定次數,但它並不總是需要運行它的過程.因此,我們必須首先在外部 for 循環的開頭設置一個布爾變量,如果在我們的排序算法期間進行交換,它將在內部循環中從 False 變為 True。
正如我們所討論的早些時候,冒泡排序算法比較兩個相鄰的值以確定是否需要更改數組。因此,我們設置一個條件來確定哪個值最高。如果第一個變量的值較高,它將與數組中的相鄰項交換位置。而且,由於已經進行了交換,我們還將布爾值 (swap) 設置為 True,這樣我們就不會跳出循環。
一旦內部循環遍歷數組第一次,布爾值將設置為 True,因此我們第二次進入外部循環,再次將布爾值(交換)設置為 False 以重新開始整個過程。這個布爾值每次都必須重新初始化,因為我們希望我們的算法能夠在我們第一次通過內部循環時退出而不進行交換。你可以在沒有退出條件的情況下完成整個過程,但你的程序執行得更快。
訪問範圍
冒泡排序算法將繼續這個過程,直到我們’在沒有進行交換的情況下,我們已經完成了內部循環的一個完整迭代。在 for 循環語法中,範圍告訴循環何時開始、停止以及遞增多少步。它可以接受三個參數,但它只需要一個參數——for 循環應該在什麼點停止。
在我們的外部 for 循環中,我們只需要告訴它在哪裡停止,也就是最後一個數組的索引。我們必須使用 z-1 作為那裡的範圍,因為索引從 0 而不是 1 開始編號。因此,如果我們離開 z,它會比我們需要的多一次。
在我們的內部for 循環,我們有兩個參數,因為我們想告訴它從哪裡開始——第一個索引 0——以及在哪裡停止。我們比外部 for 循環早一點停止,因為我們不需要檢查數組中剩餘的項目。
更新數組
if 語句創建一個條件來確定如果數組中的兩個相鄰項需要交換它們的位置。由於我們按升序對數字進行排序,如果第一個數字比第二個數字大,那麼第一個數字需要向右移動一位,這意味著第二個數字需要向左移動一位,因為它更小。
這種切換可以通過幾種不同的方式發生,但最快和最簡單的方式是同時將值分配給相鄰的項目。這是通過以下語句完成的:numArray[b], numArray[b+1]=numArray[b+1], numArray[b]。另一種方法是創建一個臨時變量來保存一個需要移動的值,而另一個通過簡單的賦值移動。但是,由於這需要更多的代碼,所以當我們同時分配它們時,完成起來會更有效率。
結果的輸出
當 bubbleSort 方法打破嵌套時for 循環並返回到主程序,它將結果數組發送到我們從中調用該方法的 print 語句,並將結果顯示在屏幕上,為我們提供一個包含七個項目的數組,這些項目按數值升序排列。
我們將從示例中得到的排序數組:
[-500,-80, 0, 2, 67, 82, 99]
冒泡排序的最佳和最差用例算法
當我們需要按特定順序排列的數據項數量有限時,冒泡排序算法可以有效地工作。當您擴大或添加太多數據點時,冒泡排序開始變得困難。如果您需要更高效的算法,有很多選擇。您可以查看合併排序和快速排序,這兩種方法都快得多。
讓我們看看時間和空間複雜度來了解性能。
冒泡排序算法的時間複雜度
(N表示數據集中的項目數。)
最好的情況是數組已經排序並且不需要進行任何更改。然而,在排序算法開始之前,程序並不知道這一點,因此它必須至少完成一次對數組進行排序的步驟。
在處理需要排序的數據時,這不是典型的做法。通常,我們正在處理用戶輸入的數據或從程序執行的另一個方法中提取的數據。並且這不是設計要求用戶按字母順序或數字順序輸入數據的程序的最有效方法。
冒泡排序算法的空間複雜度
冒泡排序算法對空間的需求不大。因為,最多,我們只是添加一個布爾值來檢查交換和臨時變量來保存數據,同時我們在必要時進行交換。因此,當我們使用更大的數據集時,空間複雜度不會改變。
總結
當您只想排序時,冒泡排序算法會很高效少量數據。但它確實不是最有效的,而且由於其性能,它並不理想。相反,它最適合作為初學者學習計算機如何執行算法的學習工具。如果你正在學習數據結構和算法課程,你將必須掌握這門課程。一旦掌握了排序算法的基礎知識,您就可以逐步學習更高效的算法。
什麼是冒泡排序算法,它是如何工作的? (With Examples) FAQs (Frequently Asked Questions)
什麼是冒泡排序算法?
冒泡排序算法是一種簡單的排序算法,比較兩個相鄰值並根據我們代碼中設置的條件進行切換。它通常使用 while 循環或 for 循環來遍歷每組相鄰項,直到它到達數據集的末尾。但是,它需要對整個數據集進行多次迭代才能按升序或降序對數據進行排序。
冒泡排序算法的局限性是什麼?
當我們擁有大量數據時,冒泡排序算法並不是我們計算機能力的最佳利用方式。其他排序算法會是更好的選擇,因為它們可能不會花費那麼多時間來執行算法。
冒泡排序算法的時間複雜度是多少?
時間複雜度範圍從 0 (N) 到 0 (N^2),其中當數據集已經排序時存在最佳情況。 N 表示數據集中的項數,因此在處理大量數據時時間複雜度會大大增加。
冒泡排序算法的空間複雜度是多少?
無論我們的數據集有多大,空間複雜度都是O(1),也就是說保持不變。理論上,如果您有一個包含 200 個項目的數據集,它佔用的空間量與包含 100 個項目的數據集相同。
什麼時候應該使用冒泡排序算法?
因為它對小數據集最有效,所以冒泡排序算法在教育環境中最有用,當初學者第一次學習如何編寫排序算法代碼時。
什麼冒泡排序算法有哪些不同的實現方式?
因為我們需要遍歷整個數據集來執行冒泡排序算法,所以通常用循環實現——要么是for循環或 while 循環。
冒泡排序算法有哪些替代方案?
我們可以使用多種算法來執行排序。以下是一些最常用的排序方法:選擇排序、插入排序、桶排序、堆排序和歸併排序。