Existem muitos algoritmos de classificação que podem ser usados para classificar conjuntos de dados. Normalmente, esses dados são apresentados em uma lista ou array. Desses algoritmos, o algoritmo de classificação por seleção é um dos mais simples de entender e implementar. Neste artigo, explicaremos a teoria por trás da classificação por seleção, como ela é implementada e as práticas recomendadas para usar o algoritmo.
O que é classificação por seleção?
Classificação por seleção é um algoritmo de classificação baseado em comparação. Funciona dividindo a matriz em duas partes – classificada e não classificada. O elemento com o menor valor é selecionado e colocado no índice 0 do subarray classificado. O maior elemento também pode ser selecionado primeiro, dependendo se você deseja que sua lista esteja em ordem crescente ou decrescente. Este é um processo iterativo, o que significa que o método é repetido até que todos os elementos sejam colocados na matriz classificada em suas posições corretas. Como você pode esperar, a cada iteração, o tamanho do subarray classificado aumenta em um elemento, enquanto o tamanho do array não classificado diminui em um elemento.
 Você pode implementar a classificação por seleção com uma variedade de linguagens de programação, incluindo C, C++, C#, PHP, Java, Javascript e Pitão.
Você pode implementar a classificação por seleção com uma variedade de linguagens de programação, incluindo C, C++, C#, PHP, Java, Javascript e Pitão.
O algoritmo por trás da classificação por seleção
O algoritmo por trás da classificação por seleção é bastante simples e segue estas etapas:
 O elemento mínimo na matriz não classificada é encontrado e trocado com o primeiro elemento, no índice 0. A matriz não classificada é então percorrido para encontrar o novo elemento mínimo. Se algum elemento for menor que o elemento no índice 0, os elementos são trocados. O próximo elemento mínimo no array não classificado é encontrado e adicionado ao subarray classificado, seguindo a restrição anterior.Esse processo é repetido até que todo o array esteja classificado.
O elemento mínimo na matriz não classificada é encontrado e trocado com o primeiro elemento, no índice 0. A matriz não classificada é então percorrido para encontrar o novo elemento mínimo. Se algum elemento for menor que o elemento no índice 0, os elementos são trocados. O próximo elemento mínimo no array não classificado é encontrado e adicionado ao subarray classificado, seguindo a restrição anterior.Esse processo é repetido até que todo o array esteja classificado.
Trabalho da classificação por seleção
Agora que vimos como funciona a classificação por seleção, é hora de ilustrar isso com um exemplo.
Se considerarmos o array [72, 61, 59, 47, 21]:
A primeira passagem, ou iteração, do processo envolve percorrer toda a matriz do índice 0 ao índice 4 (lembre-se de que o primeiro índice é definido como 0, não 1).
O elemento mínimo encontrado é 21, então este é trocado pelo primeiro elemento, 72. Isso é ilustrado abaixo.
[21, 61, 59, 47, 72]
onde verde=elemento classificado
Para a segunda passagem, descobrimos que 47 é o segundo menor valor. Isso é então trocado por 61.
[21, 47, 59, 61, 72]
A terceira passagem detecta 59 como o terceiro elemento, que já está na posição. Portanto, nenhuma troca ocorre.
[21, 47, 59, 61, 72]
A quarta passagem encontra 61 como o quarto elemento que, novamente, já está no lugar.
[21, 47, 59, 61, 72]
A quinta e última passagem resulta em praticamente o mesmo. 72 é o quinto menor, ou o maior elemento, e está na posição correta. Agora, o array está completamente ordenado em ordem crescente.
[21, 47, 59, 61, 72]
Implementação do Selection Sort
Podemos implementar classificação de seleção com uma variedade de linguagens de programação, incluindo as mais comuns – C, C++, C#, PHP, Java, Javascript e Python. Para ilustração, vamos usar Python. O código usado com Python é o seguinte:
def SSort(arr, size): for step in range(size): min_idx=step for i in range(step + 1, size): if arr[i] arr [min_idx]: min_idx=i (arr[step], arr[min_idx])=(arr[min_idx], arr[step]) data=[-7, 39, 0, 14, 7] size=len(data) SSort(data, size) print(‘Ascending Sorted Array:’) print(data)
Explicação do código
Neste estágio, uma explicação do código usado será útil. Em primeiro lugar, definimos a função “SSort” como uma função de uma matriz com um tamanho especificado.
O loop “for” determina que um loop começará a iterar em um intervalo de “size”, o que significa o comprimento da matriz. A variável “step” indica que cada iteração assumirá os valores 0, 1, 2… até tamanho-1.
A próxima linha mostra que o valor inicial de “step” é igual à variável “ min_idx”. Esta é uma maneira de controlar a posição do elemento mínimo no array não classificado.
O próximo loop “for” especifica um loop que irá iterar no array não classificado, começando em “step + 1”. Isso ocorre porque o elemento “step” já está colocado no array classificado. A variável “i” em cada iteração será equivalente ao passo + 1, passo + 2 e assim por diante até o tamanho – 1.
A instrução “if” que verifica se o elemento atual está em “i” é menor que o elemento mínimo atual. Se este for o caso, o elemento mínimo é atualizado para refletir isso.
Por último, esta linha bastante complicada tem um significado simples. Depois que o loop anterior termina, o elemento não classificado mínimo é trocado pelo primeiro elemento na matriz não classificada. Isso efetivamente adiciona o elemento ao final da matriz classificada.
O código na parte inferior simplesmente dita a matriz com a qual estamos trabalhando, de comprimento”tamanho”, e chama a classificação de seleção para trabalhar nisso variedade. A saída é então impressa com o título “Ascending Sorted Array”.
Sempre que usar Python, é fundamental que você use o recuo correto para designar as operações separadas. Caso contrário, você receberá uma mensagem de erro e o cálculo não será executado.
Como é o código
Confira a captura de tela abaixo para ver como esse código fica quando implementado em Python.
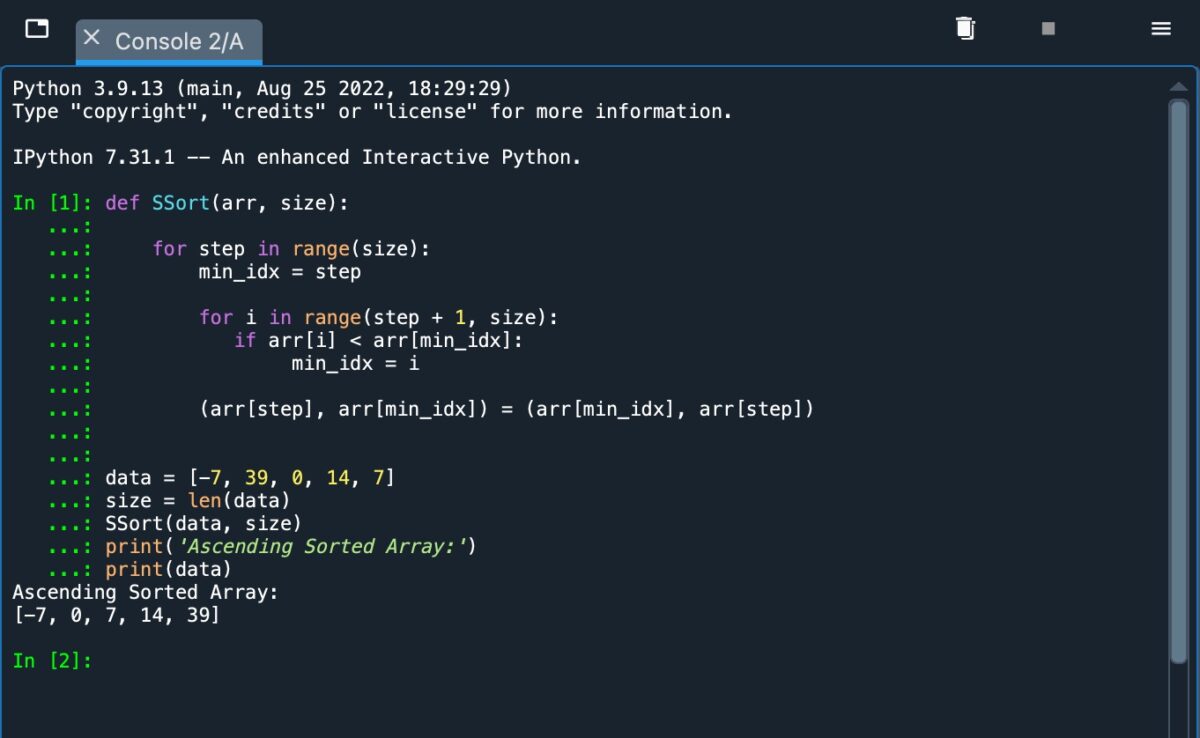 Ao usar Python, você deve usar o recuo correto para designar as operações separadas.
Ao usar Python, você deve usar o recuo correto para designar as operações separadas.
©”TNGD.com
Melhores e piores casos de uso de classificação por inserção
Embora a classificação por inserção seja útil para muitos propósitos, como em qualquer algoritmo, ele tem seus melhores e piores casos. Isso se deve principalmente à complexidade de tempo e espaço.
Complexidade de tempo com classificação por inserção
A complexidade de tempo em cada caso pode ser descrita na tabela a seguir:
Como com qualquer algoritmo, a ordenação por seleção tem sua própria complexidade de tempo e espaço. Isso basicamente se refere a como a complexidade, ou velocidade de execução, muda em uma variedade de casos. A complexidade de tempo pode ser resumida como na tabela a seguir:
O melhor caso refere-se a quando a matriz é classificada, o caso médio refere-se a quando a matriz é confusa e o pior caso refere-se a quando a matriz está em ordem crescente ou decrescente e você deseja a ordem oposta. Em outras palavras, eles se referem a quantas iterações serão necessárias para completar o processo, com o pior caso requerendo o número máximo de iterações.
Para este caso, a complexidade de tempo é idêntica para seleção ordenada em cada caso. Isso ocorre porque o algoritmo sempre executa o mesmo número de comparações e trocas, independentemente da classificação da matriz. Portanto, a complexidade é O(n2), também conhecida como tempo quadrático. Esta é uma das principais razões pelas quais o algoritmo não é muito eficiente no que diz respeito aos algoritmos de classificação, mas também significa que a eficiência não depende da distribuição da entrada.
Complexidade espacial com classificação por seleção
A complexidade do espaço refere-se à quantidade de memória necessária para os cálculos. No caso de ordenação por seleção, isso é igual a O(1). Isso significa que uma quantidade constante de memória é necessária, independentemente do tamanho da entrada. A única variável temporária armazenada é “min_idx”, que não muda com o aumento do tamanho da entrada.
Resumo
A classificação por seleção é um algoritmo relativamente simples, mas bastante ineficiente para classificar elementos em uma determinada entrada. É mais apropriado para conjuntos de dados muito pequenos e pode ser implementado com uma variedade de linguagens de programação. A classificação por seleção funciona dividindo o array em dois subarrays, classificados e não classificados. O processo então percorre uma matriz para encontrar o elemento mínimo e move esse elemento para o índice 0. O processo é repetido, encontrando o segundo e o terceiro menores elementos e assim por diante e trocando-os em suas posições de índice corretas. Isso continua até que toda a matriz seja classificada.
A seguir…
Algoritmo de classificação por seleção explicado, com exemplos Perguntas frequentes (perguntas frequentes)
O que que é classificação por seleção?
Classificação por seleção é um algoritmo de classificação simples que classifica uma matriz de elementos em ordem crescente ou decrescente. Ele faz isso percorrendo o array para encontrar o elemento mínimo e o troca pelo elemento no índice 0, em um subarray classificado. O subarray não classificado é então percorrido novamente e o elemento mínimo encontrado e trocado em sua posição correta. O algoritmo itera esse processo até que toda a matriz seja classificada. A classificação por seleção é um algoritmo de classificação simples que funciona encontrando repetidamente o elemento mínimo de uma parte não classificada da matriz e colocando-o no início da parte classificada da matriz. O algoritmo mantém dois subarrays em um determinado array.
Quais são as vantagens da classificação por seleção?
A classificação por seleção é um algoritmo muito simples de entender e implementar , e é suficiente para conjuntos de dados muito pequenos.
Quais são as desvantagens da classificação por seleção?
Como não é muito eficiente, a classificação por seleção é inadequada em lidar com grandes conjuntos de dados. Sua eficiência não depende da distribuição de entrada, mas isso também significa que é ineficiente em todos os casos, não importa o quão ordenada a matriz inicial já esteja. Também não é um algoritmo estável, o que significa que a ordem relativa de elementos iguais pode não ser preservada. Em suma, existem algoritmos de classificação superiores para a maioria dos casos, que podem se adaptar melhor à entrada em questão.
Quais situações são melhores para usar a classificação por seleção?
A classificação por seleção é melhor usada quando o tamanho da entrada é pequeno e você deseja uma solução simples e relativamente eficiente. Como a complexidade do espaço é O(1), a classificação por seleção tem vantagens se o uso da memória for algo que você precisa observar. Como ele sempre executa o mesmo número de iterações, pode ter um desempenho melhor do que alguns outros algoritmos ao classificar uma matriz que já está parcialmente classificada, pois levar o mesmo tempo é melhor do que levar mais tempo. Se você não precisa de um algoritmo de classificação estável, a classificação por seleção é uma escolha viável.
Qual é a complexidade de tempo da classificação por seleção?
O tempo a complexidade da ordenação por seleção é quadrática, representada como O(n2).
Qual é a complexidade do espaço da ordenação por seleção?
A complexidade do espaço é O( 1). Isso significa que uma quantidade constante de memória é usada para cada iteração, pois apenas uma variável temporária precisa ser armazenada. Embora o algoritmo possa ser ineficiente, a complexidade do espaço significa que ele tem vantagens em situações em que o uso da memória é restrito.
Quais são algumas alternativas para a classificação por seleção?
Muitos outros algoritmos de classificação serão mais eficientes na maioria dos casos de uso. Isso inclui classificação por mesclagem, classificação rápida e classificação por heap. Esses algoritmos tendem a ser mais adaptativos e têm uma complexidade de tempo muito melhor. Dessas alternativas, a classificação por mesclagem é o único algoritmo estável, por isso é viável onde você precisa preservar a ordem relativa de elementos iguais.
A classificação por seleção é um algoritmo estável?
Não, não é um algoritmo estável. Isso significa que, ao classificar uma matriz, os elementos de igual valor podem não ser preservados em sua ordem original após a troca.