Você precisa de ML?
O aprendizado de máquina é excelente para detectar padrões. Se você conseguir coletar um conjunto de dados limpo para sua tarefa, geralmente é apenas uma questão de tempo até que você consiga construir um modelo de ML com desempenho sobre-humano. Isso é especialmente verdadeiro em tarefas clássicas como classificação, regressão e detecção de anomalias.
Quando estiver pronto para resolver alguns de seus problemas de negócios com ML, você deve considerar onde seus modelos de ML serão executados. Para alguns, faz sentido executar uma infraestrutura de servidor. Isso tem a vantagem de manter seus modelos de ML privados, tornando mais difícil para os concorrentes alcançá-los. Além disso, os servidores podem executar uma ampla variedade de modelos. Por exemplo, os modelos GPT (que ficaram famosos com ChatGPT) atualmente exigem GPUs modernas, portanto, os dispositivos de consumo estão fora de uso a questão. Por outro lado, manter sua infraestrutura é bastante caro e, se um dispositivo de consumo pode executar seu modelo, por que pagar mais? Além disso, também pode haver questões de privacidade em que você não pode enviar dados do usuário para um servidor remoto para processamento.
No entanto, vamos supor que faça sentido usar os dispositivos iOS de seus clientes para executar um modelo de ML. O que pode dar errado?
Limitações da plataforma
Limites de memória
Dispositivos iOS têm muito menos memória de vídeo disponível do que seus equivalentes de desktop. Por exemplo, a recente Nvidia RTX 4080 Ti tem 20 GB de memória disponível. Os iPhones, por outro lado, têm memória de vídeo compartilhada com o restante da RAM no que chamam de “memória unificada”. Para referência, o iPhone 14 Pro possui 6 GB de RAM. Além disso, se você alocar mais da metade da memória, é muito provável que o iOS elimine o aplicativo para garantir que o sistema operacional permaneça responsivo. Isso significa que você pode contar com apenas 2-3 GB de memória disponível para inferência de rede neural.
Os pesquisadores normalmente treinam seus modelos para otimizar a precisão sobre o uso da memória. No entanto, também há pesquisas disponíveis sobre maneiras de otimizar a velocidade e o consumo de memória, para que você possa procurar modelos menos exigentes ou treinar um você mesmo.
Suporte de camadas de rede (operações)
A maioria das redes neurais e de ML vêm de estruturas de aprendizado profundo conhecidas e, em seguida, são convertidas em modelos CoreML com Ferramentas básicas de ML. CoreML é um mecanismo de inferência escrito pela Apple que pode executar vários modelos em dispositivos Apple. As camadas são bem otimizadas para o hardware e a lista de camadas suportadas é bastante longa, portanto, este é um excelente ponto de partida. No entanto, outras opções como Tensorflow Lite também estão disponíveis.
O A melhor maneira de ver o que é possível com CoreML é observar alguns modelos já convertidos usando visualizadores como Netron. A Apple lista alguns dos modelos oficialmente suportados, mas existem modelos de zoológicos orientados para a comunidade como bem. A lista completa de operações com suporte muda constantemente, portanto, examinar o código-fonte do Core ML Tools pode ser útil como ponto de partida. Por exemplo, se você deseja converter um modelo PyTorch, pode tentar encontrar a camada necessária aqui.
Além disso, algumas novas arquiteturas podem conter código CUDA escrito à mão para algumas das camadas. Em tais situações, você não pode esperar que o CoreML forneça uma camada predefinida. No entanto, você pode fornecer sua própria implementação se tiver um engenheiro qualificado familiarizado com a escrita Código de GPU.
No geral, o melhor conselho aqui é tentar converter seu modelo para CoreML antecipadamente, mesmo antes de treiná-lo. Se você tiver um modelo que não foi convertido imediatamente, é possível modificar a definição de rede neural em sua estrutura DL ou no código-fonte do conversor Core ML Tools para gerar um modelo CoreML válido sem a necessidade de escrever uma camada personalizada para inferência CoreML.
Validação
Bugs do mecanismo de inferência
Não há como testar todas as combinações possíveis de camadas, então o mecanismo de inferência sempre terá alguns bugs. Por exemplo, é comum ver convoluções dilatadas usarem muita memória com CoreML, provavelmente indicando uma implementação mal escrita com um kernel grande preenchido com zeros. Outro erro comum é a saída incorreta do modelo para algumas arquiteturas de modelo.
Nesse caso, a ordem das operações pode influenciar. É possível obter resultados incorretos dependendo se a ativação com convolução ou a conexão residual vem primeiro. A única maneira real de garantir que tudo esteja funcionando corretamente é pegar seu modelo, executá-lo no dispositivo pretendido e comparar o resultado com uma versão para desktop. Para este teste, é útil ter pelo menos um modelo semi-treinado disponível, caso contrário, o erro numérico pode se acumular para modelos mal inicializados aleatoriamente. Mesmo que o modelo treinado final funcione bem, os resultados podem ser bem diferentes entre o dispositivo e a área de trabalho para um modelo inicializado aleatoriamente.
Perda de precisão
iPhone usa precisão de meia precisão extensivamente para inferência. Embora alguns modelos não tenham nenhuma degradação de precisão perceptível devido a menos bits na representação de ponto flutuante, outros modelos podem sofrer. Você pode aproximar a perda de precisão avaliando seu modelo na área de trabalho com meia precisão e calculando uma métrica de teste para seu modelo. Um método ainda melhor é executá-lo em um dispositivo real para descobrir se o modelo é tão preciso quanto o pretendido.
Criação de perfil
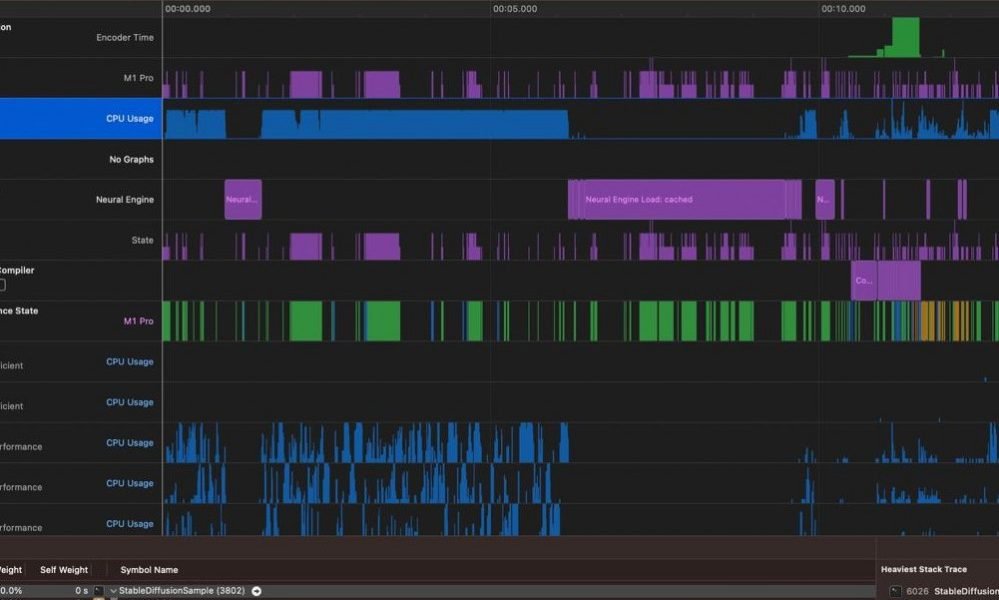
Diferentes modelos de iPhone têm recursos de hardware variados. Os mais recentes melhoraram as unidades de processamento do Neural Engine que podem elevar significativamente o desempenho geral. Eles são otimizados para determinadas operações e o CoreML é capaz de distribuir o trabalho de forma inteligente entre CPU, GPU e Neural Engine. As GPUs da Apple também melhoraram com o tempo, então é normal ver desempenhos flutuantes em diferentes modelos de iPhone. É uma boa ideia testar seus modelos em dispositivos com suporte mínimo para garantir compatibilidade máxima e desempenho aceitável para dispositivos mais antigos.
Também vale a pena mencionar que o CoreML pode otimizar algumas das camadas intermediárias e cálculos no local, o que pode melhorar drasticamente o desempenho. Outro fator a considerar é que, às vezes, um modelo com desempenho pior em um desktop pode, na verdade, fazer inferências mais rapidamente no iOS. Isso significa que vale a pena gastar algum tempo experimentando diferentes arquiteturas.
Para otimizar ainda mais, o Xcode tem uma boa ferramenta Instruments com um modelo apenas para modelos CoreML que pode fornecer uma visão mais completa sobre o que está atrasando seu inferência de modelo.
Conclusão
Ninguém pode prever todas as possíveis armadilhas ao desenvolver modelos de ML para iOS. No entanto, existem alguns erros que podem ser evitados se você souber o que procurar. Comece a converter, validar e criar perfis de seus modelos de ML com antecedência para garantir que seu modelo funcione corretamente e atenda aos seus requisitos de negócios e siga as dicas descritas acima para garantir o sucesso o mais rápido possível.