Large Language Models (LLM) como GPT3, ChatGPT e BARD estão na moda atualmente. Todo mundo tem uma opinião sobre como essas ferramentas são boas ou ruins para a sociedade e o que significam para o futuro da IA. O Google recebeu muitas críticas por seu novo modelo BARD errar (levemente) uma questão complexa. Quando perguntado “Que novas descobertas do Telescópio Espacial James Webb posso contar ao meu filho de 9 anos?” – o chatbot forneceu três respostas, das quais 2 estavam certas e 1 estava errada. A errada foi que a primeira foto do “exoplaneta” foi tirada pelo JWST, o que estava incorreto. Basicamente, o modelo tinha um fato incorreto armazenado em sua base de conhecimento. Para que modelos de linguagem grandes sejam eficazes, precisamos de uma maneira de manter esses fatos atualizados ou aumentá-los com novos conhecimentos.
Vamos primeiro ver como os fatos são armazenados dentro do modelo de linguagem grande (LLM). Modelos de linguagem grandes não armazenam informações e fatos no sentido tradicional, como bancos de dados ou arquivos. Em vez disso, eles foram treinados em grandes quantidades de dados de texto e aprenderam padrões e relacionamentos nesses dados. Isso permite que eles gerem respostas semelhantes às humanas para perguntas, mas eles não têm um local de armazenamento específico para suas informações aprendidas. Ao responder a uma pergunta, o modelo usa seu treinamento para gerar uma resposta com base na entrada que recebe. A informação e o conhecimento que um modelo de linguagem possui são resultado dos padrões que ele aprendeu nos dados em que foi treinado, não o resultado de ter sido explicitamente armazenado na memória do modelo. A arquitetura dos Transformers, na qual os LLMs mais modernos se baseiam, possui uma codificação interna de fatos usada para responder à pergunta feita no prompt.
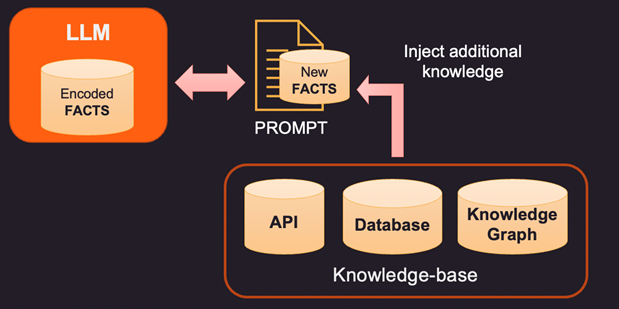
Então, se os fatos dentro da memória interna do LLM estiverem errados ou desatualizados, novas informações precisam ser fornecidas através de um prompt. Prompt é o texto enviado ao LLM com a consulta e evidências de suporte que podem ser alguns fatos novos ou corrigidos. Aqui estão 3 maneiras de abordar isso.
1. Uma maneira de corrigir os fatos codificados de um LLM é fornecer novos fatos relevantes para o contexto usando uma base de conhecimento externa. Essa base de conhecimento pode ser chamadas de API para obter informações relevantes ou uma pesquisa em um banco de dados SQL, No-SQL ou Vector. Conhecimento mais avançado pode ser extraído de um grafo de conhecimento que armazena entidades de dados e relações entre elas. Dependendo das informações que o usuário está procurando, as informações de contexto relevantes podem ser recuperadas e fornecidas como fatos adicionais ao LLM. Esses fatos também podem ser formatados para parecerem exemplos de treinamento para melhorar o processo de aprendizado. Por exemplo, você pode passar vários pares de perguntas e respostas para o modelo aprender como fornecer respostas.
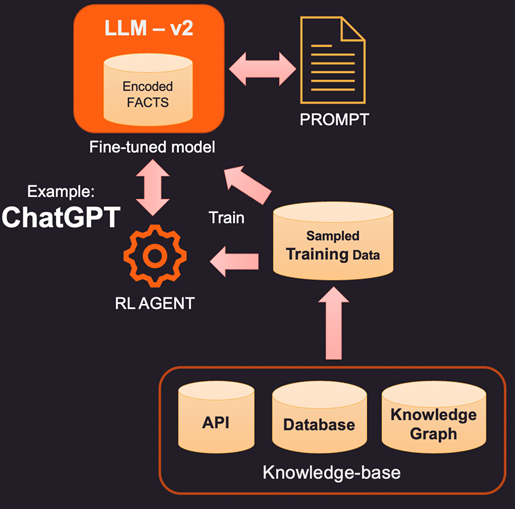
2. Uma maneira mais inovadora (e mais cara) de aumentar o LLM é o ajuste fino real usando dados de treinamento. Portanto, em vez de consultar a base de conhecimento para obter fatos específicos a serem adicionados, construímos um conjunto de dados de treinamento por amostragem da base de conhecimento. Usando técnicas de aprendizado supervisionado, como ajuste fino, poderíamos criar uma nova versão do LLM treinada com esse conhecimento adicional. Esse processo geralmente é caro e pode custar alguns milhares de dólares para construir e manter um modelo ajustado no OpenAI. Claro, espera-se que o custo fique mais barato com o tempo.
3. Outra opção é usar métodos como Reinforcement Learning (RL) para treinar um agente com feedback humano e aprender uma política sobre como responder a perguntas. Esse método tem sido altamente eficaz na construção de modelos de pegada menores que são bons em tarefas específicas. Por exemplo, o famoso ChatGPT lançado pela OpenAI foi treinado em uma combinação de aprendizado supervisionado e RL com feedback humano.
Em resumo, este é um espaço em alta evolução com todas as grandes empresas querendo entrar e mostrar sua diferenciação. Em breve, veremos as principais ferramentas LLM na maioria das áreas, como varejo, saúde e bancos, que podem responder de maneira humana, compreendendo as nuances da linguagem. Essas ferramentas com tecnologia LLM integradas aos dados corporativos podem simplificar o acesso e disponibilizar os dados certos para as pessoas certas no momento certo.