© BEST-BACKGROUNDS/Shutterstock.com
Quando se trata de classificar uma matriz de dados, há muitos algoritmos de classificação que você pode usar. Um dos algoritmos mais fáceis de usar é a classificação por inserção, devido à sua relativa simplicidade e natureza intuitiva. Continue lendo para explorar exatamente o que é classificação por inserção, como é implementada e para que pode ser usada, com um exemplo.
O que é classificação por inserção?
Classificação por inserção é uma classificação algoritmo, um dos métodos que você pode usar para classificar uma matriz. A maneira como funciona não é muito complicada de entender e pode ser amplamente comparada a como você classificaria um baralho de cartas.

Em Neste caso, começaríamos assumindo que a primeira carta do baralho já está ordenada. Em seguida, selecionamos um cartão não classificado e o classificamos. Isso é feito comparando-o com o primeiro cartão. Se a carta selecionada for maior que a carta ordenada, ela é colocada em uma posição à direita da primeira carta. Se a carta em questão for menor que a carta ordenada, ela é colocada em uma posição à esquerda.
Esse processo continua até que todos os cartões não classificados sejam colocados em suas posições corretas. A classificação por inserção funciona de maneira muito semelhante. Cada valor de dados não classificado é classificado por meio do mesmo tipo de processo iterativo.
Como a classificação por inserção é um algoritmo bastante simples, é melhor usá-lo para conjuntos de dados relativamente pequenos, bem como aqueles que já estão classificados. Desta forma, é conhecido como um algoritmo adaptativo e eficiente. Em seguida, examinaremos a teoria por trás de como a classificação por inserção funciona.
O algoritmo por trás da classificação por inserção
O método de classificação por inserção pode ser representado de forma concisa com o seguinte pseudocódigo:
insertSort(array) marca o primeiro elemento como classificado para cada elemento não classificado X’extrai’o elemento X para j-lastSortedIndex até 0 se o elemento atual j > X move o elemento classificado para a direita em 1 break loop e insere X aqui end insertSort
Em termos simples, isso significa que o primeiro elemento é considerado classificado. Cada elemento subsequente é comparado ao primeiro elemento. Se for menor que o elemento classificado, ele é movido para a primeira ou 0ª posição. Se for maior, moveu uma posição para a direita. As iterações continuam até que todos os elementos tenham sido classificados.
O funcionamento interno da classificação por inserção
Agora que abordamos como a classificação por inserção funciona e a teoria por trás dela, é hora de ilustrar o processo com uma matriz adequada. Se considerarmos o seguinte conjunto de dados:
Podemos assumir que o primeiro elemento, 10, já está classificado. Depois disso, pegamos o segundo elemento, 14, e o armazenamos separadamente. Comparando 14 com 10, podemos ver que é maior, então mantém sua posição como segundo elemento. Esta é a primeira iteração, conhecida como primeira passagem. O primeiro elemento, 10, é armazenado em um subarray.
Onde verde=array classificado
Na segunda passagem, passamos para o terceiro elemento, que é 5. Isso é em comparação com os elementos anteriores. Podemos dizer que é menor que o elemento anterior, 14, então ele troca de lugar com 14.
O algoritmo então o compara com os elementos no subarray classificado. 5 também é menor que 10, então é movido para o início do subarray. A matriz classificada agora tem 2 elementos — 5 e 10.
Agora, passamos para a terceira passagem. Neste caso, 7 é o elemento selecionado. Isso é menor que 14, então ele foi movido uma posição para a esquerda e para a matriz classificada. Esta não é a posição correta, já que 7 é menor que 10, mas maior que 5. Portanto, ele foi movido outra posição para a esquerda.
Para a quarta passagem, estamos olhando para a quarta elemento, que é 14. Isso já está classificado, então agora a matriz classificada inclui 5, 7, 10 e 14.
O resultado final
Por fim, para a quinta passagem, pegamos o quinto elemento, que é 1. Ele é claramente menor que 14, então a posição é trocada. Também é menor que 10, então a posição é trocada novamente. Isso continua mais duas vezes, pois 1 é o menor elemento da matriz. Portanto, terminamos com uma matriz classificada da seguinte forma:
A implementação da classificação por inserção
A classificação por inserção pode ser implementada com várias linguagens de programação, desde C, C# e C++ para Java, Python, PHP e Javascript. Para fins ilustrativos, vamos trabalhar com Python. Todo o processo pode ser representado no seguinte código:
def insertSort(arr): if (n:=len(arr))=1: return for i in range(1, n): key=arr[i ] j=i-1 enquanto j >=0 e tecla arr[j]: arr[j+1]=arr[j] j-=1 arr[j+1]=tecla arr=[10, 14, 5, 7, 1] insertSort(arr) print(arr)
Primeiro, estamos definindo a classificação por inserção como uma função do array, (arr). Então, estamos dizendo que, se o array tiver comprimento 1 ou menos, o array é retornado. Em seguida, estamos definindo o elemento na i-ésima posição de uma matriz de comprimento n como a chave.
Estamos colocando restrições na computação para que j só seja operado quando for maior ou igual ao índice 0. J é considerado o valor à esquerda de qualquer item que estamos olhando, como por j=i-1. Se seu valor for maior que o da chave, sua posição é deslocada para a direita.
A linha final, arr[j+1]=chave, determina que o valor à direita desse valor j se torne a nova chave. Portanto, o resto dos números são trocados conforme necessário. Esse processo continua desde o início, até que todos os números sejam classificados corretamente.
Classificação por inserção em Python: implementação
Vamos ver como isso é implementado em Python no ambiente Spyder. Usaremos a mesma matriz anterior para ilustrar isso claramente. Veja o código implementado abaixo:
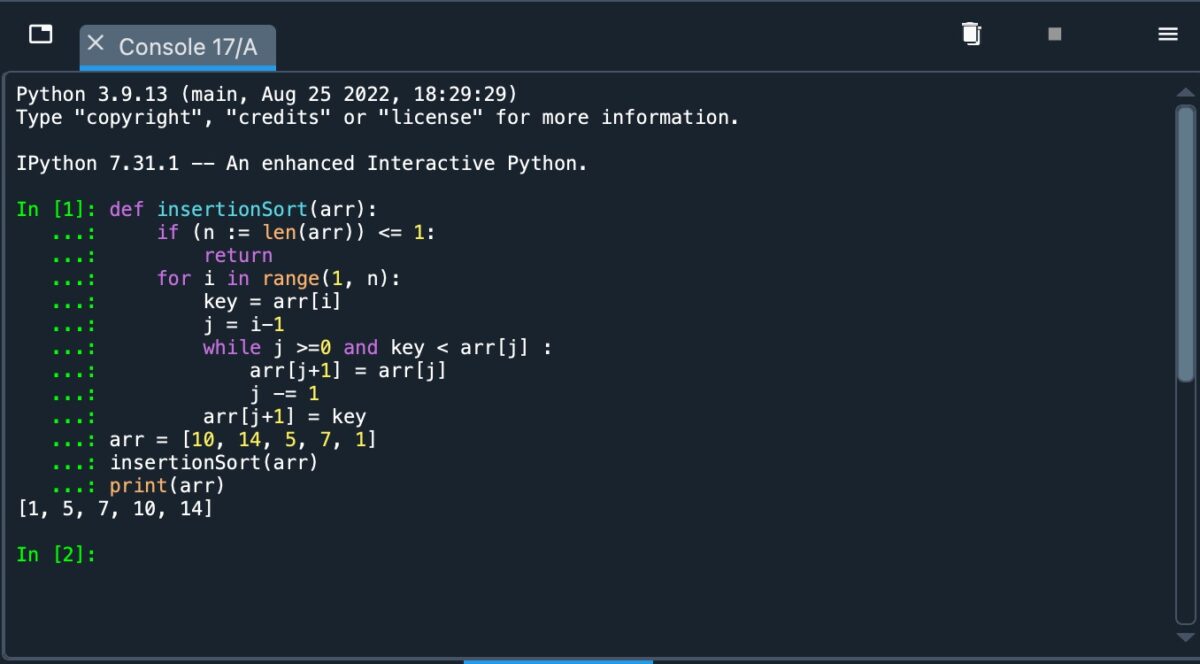 Implementando a classificação por inserção em Python.
Implementando a classificação por inserção em Python.
©”TNGD.com
Uma conclusão importante é que a indentação é crítica ao usar o Python. Se o recuo não for usado corretamente, você receberá uma mensagem de erro semelhante a algo abaixo.
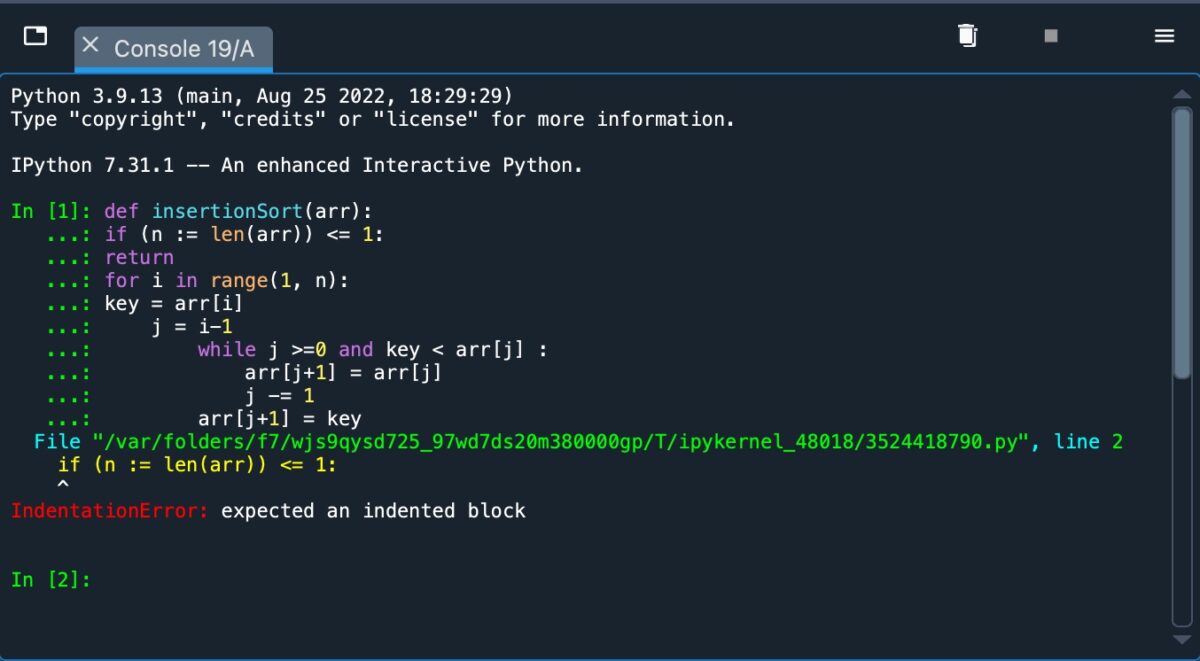 Recebendo uma mensagem de erro.
Recebendo uma mensagem de erro.
©”TNGD.com
Melhores e piores casos de uso de classificação por inserção
Embora a classificação por inserção seja útil para muitos propósitos, como em qualquer algoritmo, ela tem seus melhores e piores casos. Isso se deve principalmente à complexidade de tempo e espaço.
Complexidade de tempo com classificação por inserção
A complexidade de tempo em cada caso pode ser descrita na tabela a seguir:
Você pode ver que, no melhor caso, a complexidade de tempo é igual a O(n). Isso significa que nenhuma classificação é necessária, pois a matriz já está classificada. Como o algoritmo precisa verificar cada valor na sequência antes de poder determinar se a matriz está classificada, a complexidade de tempo é linear. Ou seja, a complexidade é linearmente proporcional ao tamanho da entrada.
Na média e nos piores casos, porém, a complexidade é igual a O(n2). Um caso médio seria onde os elementos na matriz são misturados, nem ascendentes nem descendentes. No pior caso, os elementos precisariam ser ordenados ao contrário.
Isso ocorre porque eles já estão em ordem crescente ou decrescente e você precisa da ordem oposta. Esse tipo de complexidade é conhecido como tempo quadrático porque depende de n2. Por exemplo, se o tamanho da entrada for 4, o número de operações será 16.
Complexidade de espaço com classificação por inserção
O outro tipo de complexidade é a complexidade de espaço. Isso se refere à quantidade de espaço de memória necessária para executar o algoritmo. Uma complexidade de O(1) significa que a quantidade de memória necessária é constante, independentemente do tamanho da entrada.
Isto é verdade no caso de classificação por inserção porque você está usando apenas uma variável temporária com cada operação. Em outras palavras, apenas um valor é classificado por vez, portanto, o uso da memória é constante.
Deve-se observar que a classificação por inserção é considerada um algoritmo estável, o que significa que a ordem relativa dos elementos com valores iguais é preservado. Isso é útil se você precisar preservar a ordem de elementos específicos ou precisar classificar matrizes que já estão parcialmente classificadas. Isso ocorre porque os elementos não são trocados com a chave se forem equivalentes a ela.
Resumo
Abordamos o que é classificação por inserção e quando é apropriado usá-la. Além disso, consideramos sua complexidade de tempo e espaço e mostramos sua representação e implementação de código em Python. Se você deseja classificar uma matriz relativamente pequena, especialmente uma em que alguns elementos já estão classificados, a classificação por inserção é um dos melhores métodos a usar.
Próximo
O que é Classificação por inserção e como funciona? (com exemplos) FAQs (perguntas frequentes)
O que é classificação por inserção?
Classificação por inserção é um algoritmo que pode ser usado para classificar conjuntos de dados em ordem crescente ou decrescente. É semelhante a como você classificaria um baralho de cartas em suas mãos, pois o primeiro elemento é considerado classificado.
Cada elemento subseqüente é então comparado ao primeiro elemento e colocado na posição correta, deixando-o onde está ou movendo-o uma posição para a direita. Isso é repetido para cada elemento e, em seguida, o processo continua desde o início até que todos os elementos sejam classificados.
Quando você deve usar a classificação por inserção?
A classificação por inserção é melhor usada para pequenos conjuntos de dados e aqueles em que os valores já estão parcialmente classificados.
Quais linguagens de programação podem implementar a classificação por inserção?
Muito várias linguagens de programação podem implementar a classificação por inserção, incluindo C, C++, C#, Java, Javascript, PHP e Python.
Quais são as vantagens da classificação por inserção?
As vantagens da classificação por inserção são que ela é simples, a ordem relativa das chaves não muda, é eficiente para pequenos conjuntos de dados e o fato de poder classificar uma lista enquanto ela está sendo recebida.
Como a classificação por inserção é otimizada?
A classificação por inserção é otimizada criando um subarray armazenado, onde os valores classificados são armazenados temporariamente. Isso significa que não é necessária uma troca completa dos elementos da matriz durante cada iteração, pois os elementos são trocados um por vez.
Quantas iterações existem na classificação por inserção?
Com uma matriz de comprimento n, são necessárias n-1 iterações para classificar toda a matriz.
Como a classificação por inserção pode ser modificada?
A classificação por inserção pode ser modificada usando a classificação por inserção binária. Isso é semelhante à classificação por inserção, pois é um algoritmo estável, mas reduz o número de comparações que precisam ser feitas.
A complexidade de tempo é reduzida de O(n) para O(log n) porque ele usa pesquisa binária em vez de pesquisa linear. Cada valor é comparado aos valores no subarray classificado para determinar qual valor é apenas maior que o valor selecionado. Isso reduz o número de operações.
Quais são as desvantagens da classificação por inserção?
A classificação por inserção não é apropriada para conjuntos de dados particularmente grandes, pois o a complexidade de tempo na média e no pior caso é quadrática.
Quais são as alternativas para a classificação por inserção?
Com conjuntos de dados grandes e confusos, alternativas mais apropriadas são classificação rápida, classificação por mesclagem ou classificação por heap.
A classificação por inserção é um algoritmo estável?
Sim, a classificação por inserção é considerada um algoritmo de classificação estável, porque os elementos permanecem inalterados se forem iguais à chave. A ordem dos elementos também é preservada se forem equivalentes entre si.