Los modelos de lenguaje grande (LLM) como GPT3, ChatGPT y BARD están de moda hoy en día. Todos tienen una opinión sobre cómo estas herramientas son buenas o malas para la sociedad y qué significan para el futuro de la IA. Google recibió muchas críticas por su nuevo modelo BARD y se equivocó (ligeramente) en una pregunta compleja. Cuando se le preguntó”¿Qué nuevos descubrimientos del telescopio espacial James Webb puedo contarle a mi hijo de 9 años?”– el chatbot proporcionó tres respuestas, de las cuales 2 fueron correctas y 1 incorrecta. La equivocada fue que la primera foto de”exoplaneta”fue tomada por JWST, lo cual era incorrecto. Básicamente, el modelo tenía un hecho incorrecto almacenado en su base de conocimiento. Para que los modelos de lenguaje extenso sean efectivos, necesitamos una forma de mantener estos hechos actualizados o aumentar los hechos con nuevos conocimientos.
Veamos primero cómo se almacenan los hechos dentro del modelo de lenguaje extenso (LLM). Los modelos de lenguaje grande no almacenan información y hechos en un sentido tradicional como bases de datos o archivos. En cambio, han sido entrenados en grandes cantidades de datos de texto y han aprendido patrones y relaciones en esos datos. Esto les permite generar respuestas similares a las humanas a las preguntas, pero no tienen una ubicación de almacenamiento específica para la información aprendida. Al responder una pregunta, el modelo usa su entrenamiento para generar una respuesta basada en la entrada que recibe. La información y el conocimiento que tiene un modelo de lenguaje es el resultado de los patrones que ha aprendido en los datos con los que se entrenó, no el resultado de que se haya almacenado explícitamente en la memoria del modelo. La arquitectura de Transformers en la que se basan la mayoría de los LLM modernos tiene una codificación interna de hechos que se utiliza para responder a la pregunta formulada en el aviso.
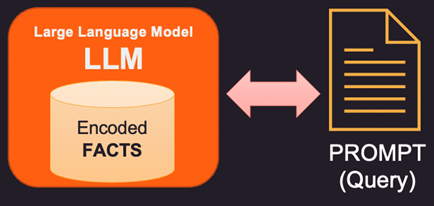
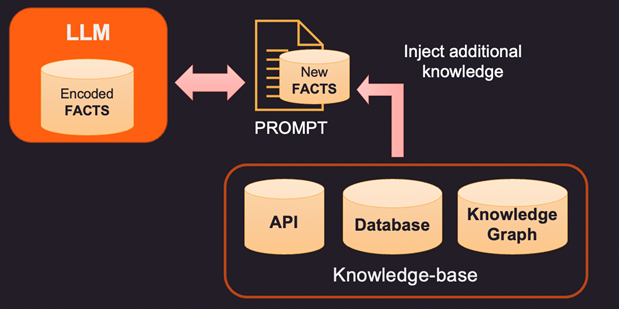
Entonces, si los datos dentro de la memoria interna del LLM son incorrectos o están obsoletos, se debe proporcionar nueva información. a través de un aviso. Prompt es el texto que se envía a LLM con la consulta y las pruebas de respaldo que pueden ser algunos hechos nuevos o corregidos. Aquí hay 3 formas de abordar esto.
1. Una forma de corregir los hechos codificados de un LLM es proporcionar nuevos hechos relevantes para el contexto utilizando una base de conocimiento externa. Esta base de conocimiento puede ser llamadas API para obtener información relevante o una búsqueda en una base de datos SQL, No-SQL o Vector. Se puede extraer conocimiento más avanzado de un gráfico de conocimiento que almacena entidades de datos y relaciones entre ellas. Dependiendo de la información que el usuario esté consultando, la información de contexto relevante puede recuperarse y proporcionarse como datos adicionales al LLM. Estos hechos también se pueden formatear para que parezcan ejemplos de capacitación para mejorar el proceso de aprendizaje. Por ejemplo, puede pasar un montón de pares de preguntas y respuestas para que el modelo aprenda a proporcionar respuestas.
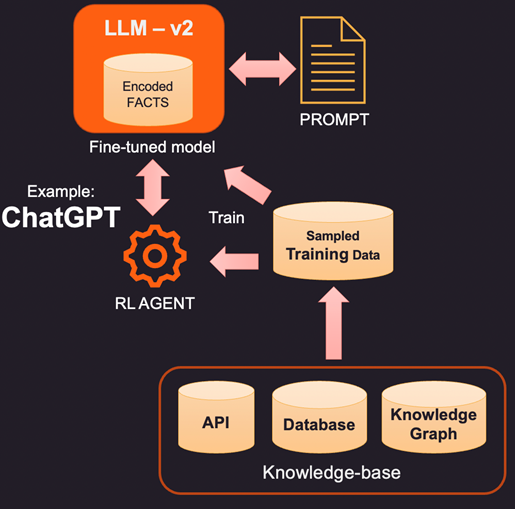
2. Una forma más innovadora (y más costosa) de aumentar el LLM es el ajuste real utilizando datos de entrenamiento. Entonces, en lugar de consultar la base de conocimiento para agregar hechos específicos, construimos un conjunto de datos de entrenamiento al muestrear la base de conocimiento. Usando técnicas de aprendizaje supervisado como el ajuste fino, podríamos crear una nueva versión del LLM que esté entrenada en este conocimiento adicional. Este proceso suele ser costoso y puede costar unos miles de dólares para construir y mantener un modelo ajustado en OpenAI. Por supuesto, se espera que el costo se abarate con el tiempo.
3. Otra opción es usar métodos como el aprendizaje por refuerzo (RL) para capacitar a un agente con comentarios humanos y aprender una política sobre cómo responder preguntas. Este método ha sido muy efectivo en la construcción de modelos de menor tamaño que funcionan bien en tareas específicas. Por ejemplo, el famoso ChatGPT lanzado por OpenAI fue entrenado en una combinación de aprendizaje supervisado y RL con retroalimentación humana.
En resumen, este es un espacio en constante evolución en el que todas las empresas importantes desean ingresar y mostrar su diferenciación. Pronto veremos las principales herramientas LLM en la mayoría de las áreas, como el comercio minorista, la atención médica y la banca, que pueden responder de manera similar a la humana y comprender los matices del lenguaje. Estas herramientas impulsadas por LLM integradas con datos empresariales pueden optimizar el acceso y hacer que los datos correctos estén disponibles para las personas adecuadas en el momento adecuado.