Le machine learning est excellent pour repérer les modèles. Si vous parvenez à collecter un ensemble de données propre pour votre tâche, ce n’est généralement qu’une question de temps avant de pouvoir créer un modèle ML avec des performances surhumaines. Cela est particulièrement vrai dans les tâches classiques telles que la classification, la régression et la détection d’anomalies.
Lorsque vous êtes prêt à résoudre certains de vos problèmes commerciaux avec ML, vous devez déterminer où vos modèles ML seront exécutés. Pour certains, il est logique d’exécuter une infrastructure de serveur. Cela a l’avantage de garder vos modèles ML privés, il est donc plus difficile pour les concurrents de rattraper leur retard. En plus de cela, les serveurs peuvent exécuter une plus grande variété de modèles. Par exemple, les modèles GPT (rendus célèbres avec ChatGPT) nécessitent actuellement des GPU modernes, de sorte que les appareils grand public sont hors de la question. D’un autre côté, la maintenance de votre infrastructure est assez coûteuse, et si un appareil grand public peut exécuter votre modèle, pourquoi payer plus ? De plus, il peut également y avoir des problèmes de confidentialité lorsque vous ne pouvez pas envoyer de données utilisateur à un serveur distant pour traitement.
Cependant, supposons qu’il soit logique d’utiliser les appareils iOS de vos clients pour exécuter un modèle ML. Qu’est-ce qui pourrait mal tourner ?
Limites de la plate-forme
Limites de mémoire
Les appareils iOS ont beaucoup moins de mémoire vidéo disponible que leurs homologues de bureau. Par exemple, la récente Nvidia RTX 4080 Ti dispose de 20 Go de mémoire disponible. Les iPhones, en revanche, ont une mémoire vidéo partagée avec le reste de la RAM dans ce qu’ils appellent la «mémoire unifiée». Pour référence, l’iPhone 14 Pro dispose de 6 Go de RAM. De plus, si vous allouez plus de la moitié de la mémoire, iOS est très susceptible de tuer l’application pour s’assurer que le système d’exploitation reste réactif. Cela signifie que vous ne pouvez compter que sur 2 à 3 Go de mémoire disponible pour l’inférence de réseau de neurones.
Les chercheurs entraînent généralement leurs modèles pour optimiser la précision par rapport à l’utilisation de la mémoire. Cependant, des recherches sont également disponibles sur les moyens d’optimiser la vitesse et l’empreinte mémoire. Vous pouvez donc soit rechercher des modèles moins exigeants, soit en former un vous-même.
Prise en charge des couches réseau (opérations)
La plupart des réseaux de ML et de neurones proviennent de cadres d’apprentissage en profondeur bien connus et sont ensuite convertis en modèles CoreML avec les outils de base de ML. CoreML est un moteur d’inférence écrit par Apple qui peut exécuter divers modèles sur les appareils Apple. Les couches sont bien optimisées pour le matériel et la liste des couches prises en charge est assez longue, c’est donc un excellent point de départ. Cependant, d’autres options comme Tensorflow Lite sont également disponibles.
Le La meilleure façon de voir ce qui est possible avec CoreML est de regarder certains modèles déjà convertis en utilisant des visualiseurs comme Netron. Apple répertorie certains des modèles officiellement pris en charge, mais il existe des zoos modèles gérés par la communauté comme bien. La liste complète des opérations prises en charge étant en constante évolution, consulter le code source de Core ML Tools peut être utile comme point de départ. Par exemple, si vous souhaitez convertir un modèle PyTorch vous pouvez essayer de trouver la couche nécessaire ici.
De plus, certaines nouvelles architectures peuvent contenir du code CUDA écrit à la main pour certaines des couches. Dans de telles situations, vous ne pouvez pas vous attendre à ce que CoreML fournisse une couche prédéfinie. Néanmoins, vous pouvez fournir votre propre implémentation si vous avez un ingénieur qualifié familier avec l’écriture Code GPU.
Dans l’ensemble, le meilleur conseil ici est d’essayer de convertir votre modèle en CoreML tôt, avant même de l’entraîner. Si vous avez un modèle qui n’a pas été converti immédiatement, il est possible de modifier la définition du réseau neuronal dans votre framework DL ou le code source du convertisseur Core ML Tools pour générer un modèle CoreML valide sans avoir besoin d’écrire une couche personnalisée pour l’inférence CoreML.
Validation
Bogues du moteur d’inférence
Il n’y a aucun moyen de tester toutes les combinaisons possibles de couches, donc le moteur d’inférence aura toujours des bogues. Par exemple, il est courant de voir des convolutions dilatées utiliser beaucoup trop de mémoire avec CoreML, indiquant probablement une implémentation mal écrite avec un gros noyau rempli de zéros. Un autre bogue courant est une sortie de modèle incorrecte pour certaines architectures de modèles.
Dans ce cas, l’ordre des opérations peut être pris en compte. Il est possible d’obtenir des résultats incorrects selon que l’activation avec convolution ou la connexion résiduelle vient en premier. Le seul véritable moyen de garantir que tout fonctionne correctement est de prendre votre modèle, de l’exécuter sur l’appareil prévu et de comparer le résultat avec une version de bureau. Pour ce test, il est utile de disposer d’au moins un modèle semi-formé, sinon l’erreur numérique peut s’accumuler pour les modèles mal initialisés de manière aléatoire. Même si le modèle formé final fonctionnera correctement, les résultats peuvent être assez différents entre l’appareil et le bureau pour un modèle initialisé de manière aléatoire.
Perte de précision
L’iPhone utilise une précision de demi-précision abondamment pour l’inférence. Alors que certains modèles n’ont pas de dégradation notable de la précision en raison du nombre réduit de bits dans la représentation en virgule flottante, d’autres modèles peuvent en souffrir. Vous pouvez approximer la perte de précision en évaluant votre modèle sur le bureau avec une demi-précision et en calculant une métrique de test pour votre modèle. Une méthode encore meilleure consiste à l’exécuter sur un appareil réel pour savoir si le modèle est aussi précis que prévu.
Profilage
Les différents modèles d’iPhone ont des capacités matérielles variées. Les derniers ont amélioré les unités de traitement Neural Engine qui peuvent augmenter considérablement les performances globales. Ils sont optimisés pour certaines opérations et CoreML est capable de répartir intelligemment le travail entre le CPU, le GPU et le Neural Engine. Les GPU Apple se sont également améliorés au fil du temps, il est donc normal de voir des performances fluctuantes entre les différents modèles d’iPhone. C’est une bonne idée de tester vos modèles sur des appareils peu pris en charge pour garantir une compatibilité maximale et des performances acceptables pour les appareils plus anciens.
Il convient également de mentionner que CoreML peut optimiser certaines des couches intermédiaires et des calculs en place, ce qui peut améliorer considérablement les performances. Un autre facteur à prendre en compte est que parfois, un modèle qui fonctionne moins bien sur un ordinateur de bureau peut en fait faire des inférences plus rapidement sur iOS. Cela signifie qu’il vaut la peine de passer du temps à expérimenter différentes architectures.
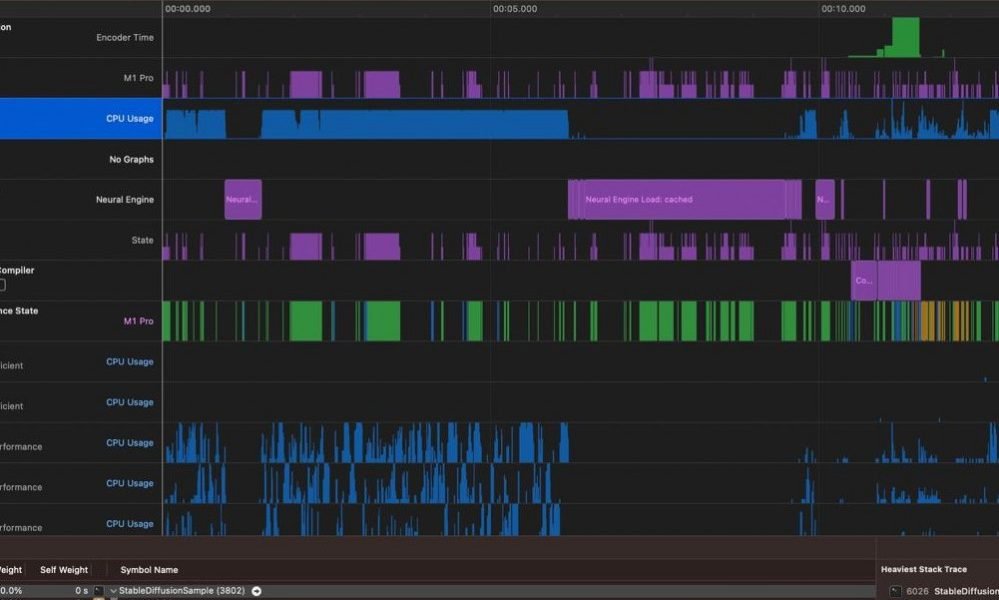
Pour encore plus d’optimisation, Xcode dispose d’un bel outil Instruments avec un modèle uniquement pour les modèles CoreML qui peut donner un aperçu plus approfondi de ce qui ralentit votre inférence de modèle.
Conclusion
Personne ne peut prévoir tous les pièges possibles lors du développement de modèles ML pour iOS. Cependant, certaines erreurs peuvent être évitées si vous savez ce qu’il faut rechercher. Commencez tôt à convertir, valider et profiler vos modèles de ML pour vous assurer que votre modèle fonctionnera correctement et répondra aux besoins de votre entreprise, et suivez les conseils décrits ci-dessus pour assurer le succès le plus rapidement possible.