Les grands modèles linguistiques (LLM) comme GPT3, ChatGPT et BARD font fureur aujourd’hui. Tout le monde a une opinion sur la façon dont ces outils sont bons ou mauvais pour la société et ce qu’ils signifient pour l’avenir de l’IA. Google a reçu beaucoup de critiques pour son nouveau modèle BARD qui s’est trompé (légèrement) sur une question complexe. Lorsqu’on lui a demandé”De quelles nouvelles découvertes du télescope spatial James Webb puis-je parler à mon enfant de 9 ans ?”– le chatbot a fourni trois réponses, dont 2 bonnes et 1 mauvaise. La mauvaise était que la première photo”d’exoplanète”avait été prise par JWST, ce qui était incorrect. Donc, fondamentalement, le modèle avait un fait incorrect stocké dans sa base de connaissances. Pour que les grands modèles de langage soient efficaces, nous avons besoin d’un moyen de maintenir ces faits à jour ou d’augmenter les faits avec de nouvelles connaissances.
Regardons d’abord comment les faits sont stockés à l’intérieur du grand modèle de langage (LLM). Les grands modèles de langage ne stockent pas les informations et les faits au sens traditionnel comme les bases de données ou les fichiers. Au lieu de cela, ils ont été formés sur de grandes quantités de données textuelles et ont appris des modèles et des relations dans ces données. Cela leur permet de générer des réponses de type humain aux questions, mais ils n’ont pas d’emplacement de stockage spécifique pour leurs informations apprises. Lorsqu’il répond à une question, le modèle utilise sa formation pour générer une réponse basée sur l’entrée qu’il reçoit. Les informations et les connaissances dont dispose un modèle de langage sont le résultat des modèles qu’il a appris dans les données sur lesquelles il a été formé, et non le résultat de leur stockage explicite dans la mémoire du modèle. L’architecture Transformers sur laquelle reposent la plupart des LLM modernes possède un codage interne des faits qui est utilisé pour répondre à la question posée dans l’invite.
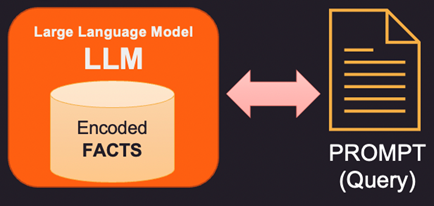
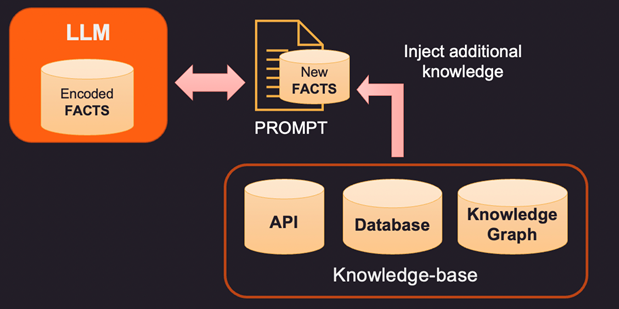
Ainsi, si les faits contenus dans la mémoire interne du LLM sont erronés ou obsolètes, de nouvelles informations doivent être fournies via une invite. L’invite est le texte envoyé à LLM avec la requête et les preuves à l’appui qui peuvent être des faits nouveaux ou corrigés. Voici 3 façons d’aborder cela.
1. Une façon de corriger les faits codés d’un LLM est de fournir de nouveaux faits pertinents au contexte en utilisant une base de connaissances externe. Cette base de connaissances peut être des appels d’API pour obtenir des informations pertinentes ou une recherche sur une base de données SQL, No-SQL ou Vector. Des connaissances plus avancées peuvent être extraites d’un graphe de connaissances qui stocke les entités de données et les relations entre elles. En fonction des informations que l’utilisateur recherche, les informations de contexte pertinentes peuvent être récupérées et fournies en tant que faits supplémentaires au LLM. Ces faits peuvent également être formatés pour ressembler à des exemples de formation afin d’améliorer le processus d’apprentissage. Par exemple, vous pouvez passer un tas de paires de questions-réponses pour que le modèle apprenne à fournir des réponses.
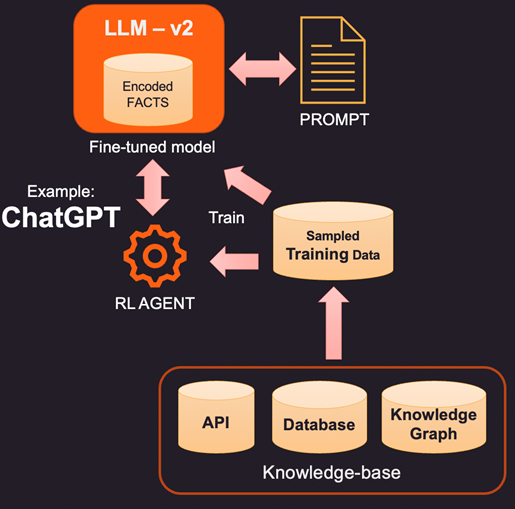
2. Un moyen plus innovant (et plus coûteux) d’augmenter le LLM est un réglage précis à l’aide de données de formation. Ainsi, au lieu d’interroger la base de connaissances pour des faits spécifiques à ajouter, nous construisons un ensemble de données de formation en échantillonnant la base de connaissances. En utilisant des techniques d’apprentissage supervisé comme le réglage fin, nous pourrions créer une nouvelle version du LLM qui est formée sur ces connaissances supplémentaires. Ce processus est généralement coûteux et peut coûter quelques milliers de dollars pour créer et maintenir un modèle affiné dans OpenAI. Bien sûr, le coût devrait diminuer avec le temps.
3. Une autre option consiste à utiliser des méthodes telles que l’apprentissage par renforcement (RL) pour former un agent avec une rétroaction humaine et apprendre une politique sur la façon de répondre aux questions. Cette méthode s’est avérée très efficace pour créer des modèles à empreinte réduite qui s’avèrent efficaces pour des tâches spécifiques. Par exemple, le célèbre ChatGPT publié par OpenAI a été formé sur une combinaison d’apprentissage supervisé et de RL avec rétroaction humaine.
En résumé, il s’agit d’un espace en pleine évolution où chaque grande entreprise souhaite entrer et montrer sa différenciation. Nous verrons bientôt des outils LLM majeurs dans la plupart des domaines comme la vente au détail, la santé et la banque qui peuvent répondre de manière humaine en comprenant les nuances du langage. Ces outils alimentés par LLM intégrés aux données d’entreprise peuvent rationaliser l’accès et mettre les bonnes données à la disposition des bonnes personnes au bon moment.