Des termes tels que l’intelligence artificielle (IA), l’apprentissage automatique (ML) et l’apprentissage en profondeur sont à la mode ces jours-ci. Les gens, cependant, utilisent souvent ces termes de manière interchangeable. Bien que ces termes soient étroitement liés les uns aux autres, ils ont également des caractéristiques distinctives et des cas d’utilisation spécifiques.
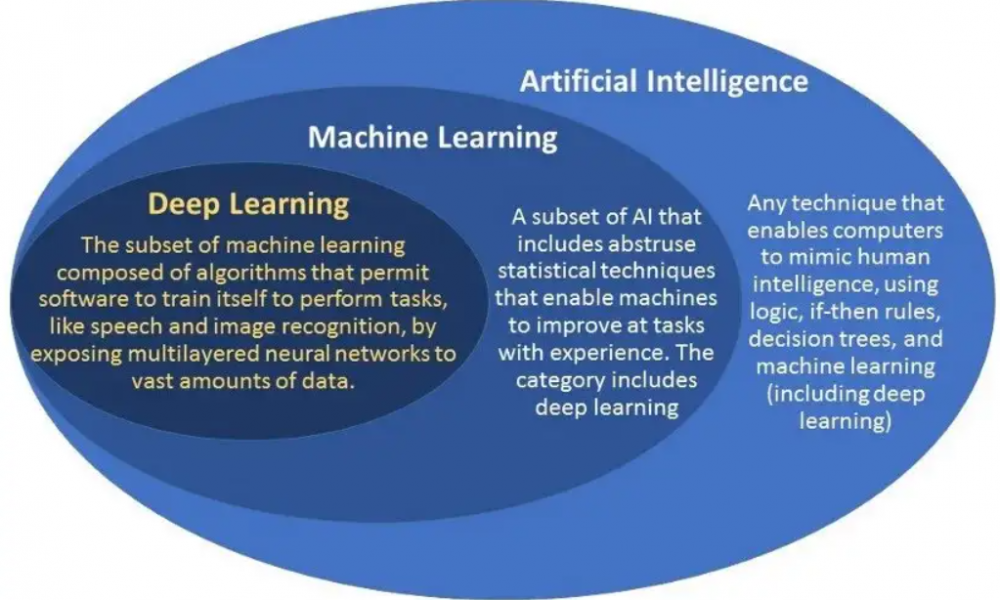
L’IA concerne des machines automatisées qui résolvent des problèmes et prennent des décisions en imitant les capacités cognitives humaines. L’apprentissage automatique et l’apprentissage en profondeur sont les sous-domaines de l’IA. L’apprentissage automatique est une IA qui peut faire des prédictions avec une intervention humaine minimale. Alors que l’apprentissage en profondeur est le sous-ensemble de l’apprentissage automatique qui utilise des réseaux de neurones pour prendre des décisions en imitant les processus neuronaux et cognitifs de l’esprit humain.
L’image ci-dessus illustre la hiérarchie. Nous continuerons en expliquant les différences entre l’apprentissage automatique et l’apprentissage en profondeur. Il vous aidera également à choisir la méthodologie appropriée en fonction de son application et de son domaine d’intérêt. Discutons-en en détail.
L’apprentissage automatique en bref
L’apprentissage automatique permet aux experts de”former”une machine en lui faisant analyser des ensembles de données massifs. Plus la machine analyse de données, plus elle peut produire des résultats précis en prenant des décisions et en faisant des prédictions pour des événements ou des scénarios invisibles.
Les modèles de machine learning ont besoin de données structurées pour faire des prédictions et des décisions précises. Si les données ne sont pas étiquetées et organisées, les modèles d’apprentissage automatique ne parviennent pas à les comprendre avec précision, et cela devient un domaine d’apprentissage en profondeur.
La disponibilité de volumes de données gigantesques dans les organisations a fait de l’apprentissage automatique une partie intégrante de la prise de décision. Les moteurs de recommandation sont l’exemple parfait des modèles d’apprentissage automatique. Les services OTT comme Netflix apprennent vos préférences de contenu et suggèrent un contenu similaire en fonction de vos habitudes de recherche et de votre historique de visionnage.
Pour comprendre comment les modèles d’apprentissage automatique sont entraînés, examinons d’abord les types de ML.
Il existe quatre types de méthodologies dans l’apprentissage automatique.
Apprentissage supervisé-Il a besoin de données étiquetées pour donner des résultats précis. Cela nécessite souvent d’apprendre plus de données et des ajustements périodiques pour améliorer les résultats.Semi-supervisé-C’est un niveau intermédiaire entre l’apprentissage supervisé et non supervisé qui présente la fonctionnalité des deux domaines. Il peut donner des résultats sur des données partiellement étiquetées et ne nécessite pas d’ajustements continus pour donner des résultats précis.Apprentissage non supervisé-Il découvre des modèles et des informations dans des ensembles de données sans intervention humaine et donne des résultats précis. Le regroupement est l’application la plus courante de l’apprentissage non supervisé. Apprentissage par renforcement-Le modèle d’apprentissage par renforcement nécessite une rétroaction ou un renforcement constant à mesure que de nouvelles informations arrivent pour donner des résultats précis. Il utilise également une”fonction de récompense”qui permet l’auto-apprentissage en récompensant les résultats souhaités et en pénalisant les mauvais résultats.
L’apprentissage en profondeur en bref
Les modèles d’apprentissage automatique nécessitent une intervention humaine pour améliorer la précision. Au contraire, les modèles d’apprentissage en profondeur s’améliorent après chaque résultat sans supervision humaine. Mais cela nécessite souvent des volumes de données plus détaillés et plus longs.
La méthodologie d’apprentissage en profondeur conçoit un modèle d’apprentissage sophistiqué basé sur des réseaux de neurones inspirés de l’esprit humain. Ces modèles ont plusieurs couches d’algorithmes appelés neurones. Ils continuent de s’améliorer sans intervention humaine, comme l’esprit cognitif qui ne cesse de s’améliorer et d’évoluer avec la pratique, les revisites et le temps.
Les modèles d’apprentissage en profondeur sont principalement utilisés pour la classification et l’extraction de caractéristiques. Par exemple, les modèles profonds se nourrissent d’un jeu de données en reconnaissance faciale. Le modèle crée des matrices multidimensionnelles pour mémoriser chaque caractéristique faciale sous forme de pixels. Lorsque vous lui demandez de reconnaître une photo d’une personne à laquelle il n’a pas été exposé, il la reconnaît facilement en faisant correspondre des traits faciaux limités.
Réseaux de neurones convolutifs (CNN)-La convolution est le processus d’attribution de poids à différents objets d’un image. Sur la base de ces pondérations attribuées, le modèle CNN le reconnaît. Les résultats sont basés sur la proximité de ces poids par rapport au poids de l’objet alimenté en train.Réseau neuronal récurrent (RNN)-Contrairement à CNN, le modèle RNN revisite les résultats et les points de données précédents pour prendre des décisions et des prévisions plus précises. C’est une réplique réelle de la fonctionnalité cognitive humaine.Réseaux antagonistes génératifs (GAN)- Les deux classificateurs du GAN, le générateur et le discriminateur, accèdent aux mêmes données. Le générateur produit de fausses données en incorporant la rétroaction du discriminateur. Le discriminateur essaie de classer si une donnée donnée est vraie ou fausse.
Différences saillantes
Voici quelques différences notables.