Brauchen Sie ML?
Maschinelles Lernen eignet sich hervorragend zum Erkennen von Mustern. Wenn Sie es schaffen, einen sauberen Datensatz für Ihre Aufgabe zu sammeln, ist es normalerweise nur eine Frage der Zeit, bis Sie in der Lage sind, ein ML-Modell mit übermenschlicher Leistung zu erstellen. Dies gilt insbesondere für klassische Aufgaben wie Klassifizierung, Regression und Anomalieerkennung.
Wenn Sie bereit sind, einige Ihrer geschäftlichen Probleme mit ML zu lösen, müssen Sie überlegen, wo Ihre ML-Modelle ausgeführt werden sollen. Für einige macht es Sinn, eine Serverinfrastruktur zu betreiben. Dies hat den Vorteil, dass Ihre ML-Modelle privat bleiben, sodass es für Konkurrenten schwieriger ist, aufzuholen. Darüber hinaus können Server eine größere Vielfalt von Modellen ausführen. Zum Beispiel erfordern GPT-Modelle (berühmt geworden durch ChatGPT) derzeit moderne GPUs, sodass Consumer-Geräte ausfallen die Frage. Andererseits ist die Wartung Ihrer Infrastruktur ziemlich kostspielig, und wenn ein Verbrauchergerät Ihr Modell ausführen kann, warum dann mehr bezahlen? Darüber hinaus kann es auch Datenschutzbedenken geben, wenn Sie Benutzerdaten nicht zur Verarbeitung an einen Remote-Server senden können.
Nehmen wir jedoch an, dass es sinnvoll ist, die iOS-Geräte Ihrer Kunden zum Ausführen eines ML-Modells zu verwenden. Was könnte schief gehen?
Plattformeinschränkungen
Speicherbeschränkungen
iOS-Geräte haben weitaus weniger verfügbaren Videospeicher als ihre Desktop-Pendants. Beispielsweise verfügt die aktuelle Nvidia RTX 4080 Ti über 20 GB verfügbaren Speicher. Auf der anderen Seite haben iPhones einen Videospeicher, der mit dem Rest des RAMs geteilt wird, was sie als „einheitlichen Speicher“ bezeichnen. Als Referenz verfügt das iPhone 14 Pro über 6 GB RAM. Wenn Sie mehr als die Hälfte des Speichers zuweisen, beendet iOS sehr wahrscheinlich die App, um sicherzustellen, dass das Betriebssystem reaktionsfähig bleibt. Das bedeutet, dass Sie sich darauf verlassen können, dass nur 2–3 GB verfügbarer Speicher für neuronale Netzwerk-Inferenz zur Verfügung stehen.
Forscher trainieren ihre Modelle normalerweise, um die Genauigkeit gegenüber der Speichernutzung zu optimieren. Es gibt jedoch auch Untersuchungen zu Möglichkeiten zur Optimierung der Geschwindigkeit und des Speicherbedarfs, sodass Sie entweder nach weniger anspruchsvollen Modellen suchen oder selbst eines trainieren können.
Unterstützung von Netzwerkschichten (Operationen)
Die meisten ML-und neuronalen Netze stammen aus bekannten Deep-Learning-Frameworks und werden dann in CoreML-Modelle konvertiert mit Core ML Tools. CoreML ist eine von Apple geschriebene Inferenz-Engine, die verschiedene Modelle auf Apple-Geräten ausführen kann. Die Schichten sind gut für die Hardware optimiert und die Liste der unterstützten Schichten ist ziemlich lang, daher ist dies ein ausgezeichneter Ausgangspunkt. Es sind jedoch auch andere Optionen wie Tensorflow Lite verfügbar.
Die Der beste Weg, um zu sehen, was mit CoreML möglich ist, ist, sich einige bereits konvertierte Modelle mit Viewern wie Netron anzusehen. Apple listet einige der offiziell unterstützten Modelle auf, aber es gibt von der Community betriebene Modellzoos wie Also. Die vollständige Liste der unterstützten Vorgänge ändert sich ständig, daher kann ein Blick auf den Quellcode der Core ML Tools als Ausgangspunkt hilfreich sein. Wenn Sie beispielsweise ein PyTorch-Modell konvertieren möchten, können Sie versuchen, die erforderliche Ebene zu finden hier.
Außerdem können bestimmte neue Architekturen handgeschriebenen CUDA-Code für einige der Schichten enthalten. In solchen Situationen können Sie nicht erwarten, dass CoreML eine vordefinierte Ebene bereitstellt. Dennoch können Sie Ihre eigene Implementierung bereitstellen, wenn Sie einen erfahrenen Ingenieur haben, der mit dem Schreiben vertraut ist GPU-Code.
Insgesamt ist der beste Rat hier, zu versuchen, Ihr Modell frühzeitig in CoreML zu konvertieren, noch bevor Sie es trainieren. Wenn Sie ein Modell haben, das nicht sofort konvertiert wurde, ist es möglich, die neuronale Netzwerkdefinition in Ihrem DL-Framework oder im Quellcode des Core ML Tools-Konverters zu ändern, um ein gültiges CoreML-Modell zu generieren, ohne dass eine benutzerdefinierte Ebene für die CoreML-Inferenz geschrieben werden muss.
Validierung
Inferenz-Engine-Fehler
Es gibt keine Möglichkeit, jede mögliche Kombination von Ebenen zu testen, daher wird die Inferenz-Engine immer einige Fehler aufweisen. Beispielsweise ist es üblich, dass erweiterte Faltungen mit CoreML viel zu viel Speicher verbrauchen, was wahrscheinlich auf eine schlecht geschriebene Implementierung mit einem großen, mit Nullen aufgefüllten Kernel hinweist. Ein weiterer häufiger Fehler ist die falsche Modellausgabe für einige Modellarchitekturen.
In diesem Fall kann die Reihenfolge der Operationen eine Rolle spielen. Es ist möglich, falsche Ergebnisse zu erhalten, je nachdem, ob die Aktivierung mit Faltung oder die Restverbindung zuerst erfolgt. Der einzige wirkliche Weg, um sicherzustellen, dass alles richtig funktioniert, besteht darin, Ihr Modell zu nehmen, es auf dem vorgesehenen Gerät auszuführen und das Ergebnis mit einer Desktop-Version zu vergleichen. Für diesen Test ist es hilfreich, zumindest ein halb trainiertes Modell zur Verfügung zu haben, da sich sonst der numerische Fehler bei schlecht zufällig initialisierten Modellen häufen kann. Auch wenn das endgültige trainierte Modell gut funktionieren wird, können die Ergebnisse zwischen dem Gerät und dem Desktop für ein zufällig initialisiertes Modell ziemlich unterschiedlich sein.
Präzisionsverlust
Das iPhone verwendet eine Genauigkeit mit halber Genauigkeit ausführlich für Rückschlüsse. Während einige Modelle aufgrund weniger Bits in der Fließkommadarstellung keine merkliche Verschlechterung der Genauigkeit aufweisen, können andere Modelle darunter leiden. Sie können den Genauigkeitsverlust annähern, indem Sie Ihr Modell auf dem Desktop mit halber Genauigkeit auswerten und eine Testmetrik für Ihr Modell berechnen. Eine noch bessere Methode ist es, es auf einem tatsächlichen Gerät auszuführen, um herauszufinden, ob das Modell so genau wie beabsichtigt ist.
Profilerstellung
Verschiedene iPhone-Modelle haben unterschiedliche Hardwarefähigkeiten. Die neuesten haben verbesserte Neural Engine-Verarbeitungseinheiten, die die Gesamtleistung erheblich steigern können. Sie sind für bestimmte Operationen optimiert, und CoreML ist in der Lage, die Arbeit intelligent zwischen CPU, GPU und Neural Engine zu verteilen. Apple-GPUs haben sich im Laufe der Zeit ebenfalls verbessert, daher ist es normal, dass die Leistung bei verschiedenen iPhone-Modellen schwankt. Es ist eine gute Idee, Ihre Modelle auf minimal unterstützten Geräten zu testen, um maximale Kompatibilität und akzeptable Leistung für ältere Geräte sicherzustellen.
Es ist auch erwähnenswert, dass CoreML einige der Zwischenschichten und Berechnungen an Ort und Stelle optimieren kann, was die Leistung drastisch verbessern kann. Ein weiterer zu berücksichtigender Faktor ist, dass manchmal ein Modell, das auf einem Desktop schlechter abschneidet, unter iOS tatsächlich schneller inferieren kann. Das bedeutet, dass es sich lohnt, einige Zeit damit zu verbringen, mit verschiedenen Architekturen zu experimentieren.
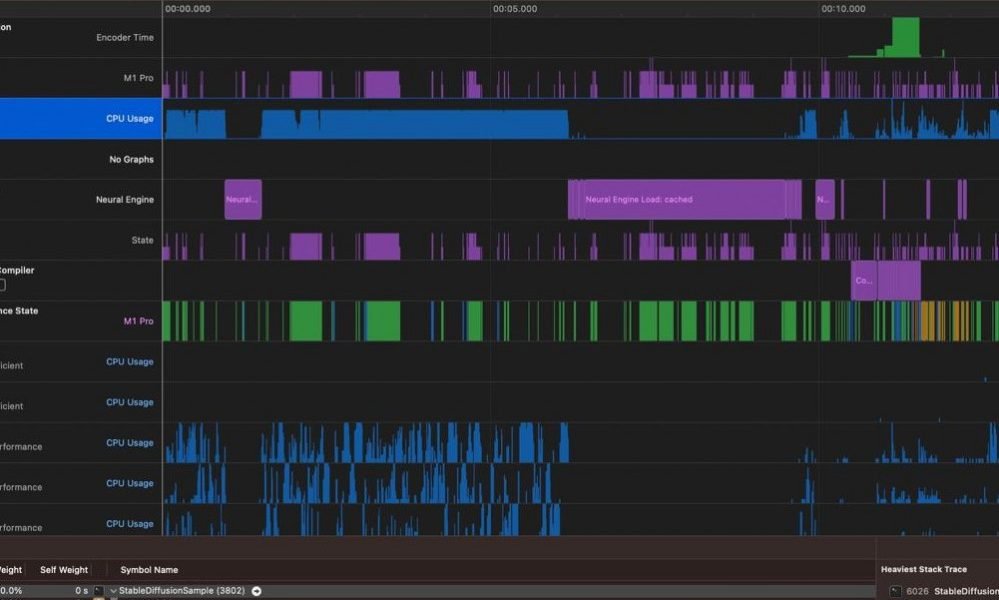
Für noch mehr Optimierung hat Xcode ein nettes Instruments-Tool mit einer Vorlage nur für CoreML-Modelle, die einen gründlicheren Einblick in das geben kann, was Sie verlangsamt Modellrückschluss.
Schlussfolgerung
Niemand kann alle möglichen Fallstricke bei der Entwicklung von ML-Modellen für iOS vorhersehen. Es gibt jedoch einige Fehler, die vermieden werden können, wenn Sie wissen, worauf Sie achten müssen. Beginnen Sie frühzeitig mit der Konvertierung, Validierung und Profilerstellung Ihrer ML-Modelle, um sicherzustellen, dass Ihr Modell ordnungsgemäß funktioniert und Ihren Geschäftsanforderungen entspricht, und befolgen Sie die oben aufgeführten Tipps, um den Erfolg so schnell wie möglich sicherzustellen.