Manchmal hat das Leben eine komische Art, sich Gelegenheiten zu bieten, und eine bot sich an, als Patrick von ServeTheHome streckte die Hand aus und sagte:”Jeff, ich habe einen Ampere Altra Max-Server. Willst du ihn dir ansehen?”
Natürlich wollte ich.
Aber da Patrick mehr als 800 ist Meilen entfernt musste ich mir einen Grund einfallen lassen, um es mir anzusehen, also holte ich meinen 6-Knoten-Raspberry-Pi-Cluster heraus – mit seinen 24 ARM Cortex A72-CPU-Kernen – und beschloss, einen kleinen Wettbewerb zu veranstalten.
Und natürlich wird dieser Wettbewerb in einem YouTube-Video dokumentiert:
In dem Video sprechen Patrick und ich ausführlich über Bereiche, in denen ARM in Unternehmen stark ist, im Vergleich zu Bereichen, in denen Intel und AMD immer noch dominieren. Als Zusammenfassung auf hoher Ebene:
ARM eignet sich hervorragend für die Integer-Leistung und für Workloads wie das Ausführen von Webservern und VMs. x86 ist großartig in Gleitkommaleistung und Rechendichte, insbesondere mit der neuesten Generation von AMD EPYC CPUs („Genoa“ – und Intels Sapphire Rapids Xeon Prozessoren sind bald erhältlich!). Das ARM-Ökosystem ist so weit gereift, dass es für Unternehmen bereit ist, obwohl es nicht ohne Warzen ist, und während SystemReady ist ein Schritt in die richtige Richtung, das x86-Ökosystem hat von vielen Jahren relativer Stabilität profitiert. Es gibt jetzt robuste und flexible ARM-Hardwareoptionen von einer Reihe von Hardwareherstellern wie Gigabyte, Asa und Supermicro – einschließlich einer Bestie einer GPU-zentrierten Maschine, die ServeTheHome bald überprüfen wird!
Aber in diesem Blogbeitrag wollte ich mich auf das von uns durchgeführte Benchmarking konzentrieren und darauf, wie verschiedene ARM-Systeme – einschließlich Apples M1 – in Bezug auf historische Top-500-Platzierungen und Leistungseffizienz abschneiden.
Benchmarking von ARM CPUs
Der plattformübergreifende Benchmark scheint heutzutage Geekbench 5 zu sein, hauptsächlich aus diesen Gründen:
Es ist einfach auszuführen. Es läuft auf (fast) jeder Plattform. Es gibt einen einfachen Single-Core + Multicore-Score
Und es ist keine schlechte Methode, um sich schnell ein Bild vom Potenzial einer CPU zu machen. Aber meine Hauptbeschwerde – da ich verstehe, dass es sich um einen einfachen Benchmark handelt, der nicht eng mit realen Anwendungsbenchmarks verbunden ist – ist, dass er wirklich nur die Spitzenleistung testet.

Der andere große Fehler— zumindest für mein Cluster-Benchmarking – ist, dass es sich nur um einen einzelnen Knoten handelt. Es ist nicht so nützlich, wenn Sie die Rechenleistung eines vollständigen Clusters testen möchten.
Und deshalb stütze ich mich auf Linpack. HPL ist nicht fehlerfrei, aber eine Sache, die es sehr gut macht, ist, ein breiteres Spektrum an CPU-Leistung zu erfassen, insbesondere bei längerer Last, und besonders in geclusterten Umgebungen über MPI.
Viele Systeme brechen auseinander, wenn man sie quält, indem man alle Kerne für 30+ Minuten auf 100 % hochfährt.
Außerdem… es macht irgendwie Spaß der Systemadministrator in mir, um zu sehen, wie mein Build schneidet historisch mit den 500 besten Supercomputern ab.
Aber ich hatte ein Problem: HPL ist schwer über mehrere Architekturen hinweg zum Laufen zu bringen und Arten von Systemen. Der Versuch, es auf Nischen-Setups (wie Raspberry Pi-Clustern) zum Laufen zu bringen, führt Sie in ein Kaninchenloch mit veralteten Blog-Posts und kniffligen Hacks.
Nachdem ich also in den letzten Jahren an der Automatisierung der HPL-Läufe gearbeitet habe, habe ich schließlich ein neues Projekt einrichten, top500-benchmark, das derzeit auf Ubuntu und Debian abzielt und entweder auf einem einzelnen Knoten oder läuft ein Cluster.
Ich habe es mit meinem Pi-Cluster, mit meinem AMD Ryzen 5 5600x-Desktop, mit Patricks Supermicro Ampere Altra Max-System und sogar mit meinem M1 Max Mac Mini (über Docker) getestet!
Das Playbook kompiliert MPI, versucht, den CPU-Skalierungsregler des Systems in den „Performance“-Modus zu versetzen (ansonsten können die Ergebnisse etwas instabil sein), kompiliert ATLAS, kompiliert dann HPL und führt es unter Verwendung einer anpassbaren HPL.dat-Datei aus.
Hilfe zum Ausführen des Setups auf Ihrem eigenen Server oder Cluster finden Sie im Projekt R EADME. Es kann immer noch ein paar Fehler geben, da ich nur 6 verschiedene Systeme (2 Cluster und 4 Workstations/Server) getestet habe, aber fühlen Sie sich frei, ein Problem zu öffnen, wenn Sie auf irgendwelche Probleme stoßen!
Ergebnisse
Die Pis sind langsam, aber relativ effizient und schlagen mein Ryzen 5 5600x-System – zugegebenermaßen in einem Build, der nicht gut auf Effizienz optimiert ist.
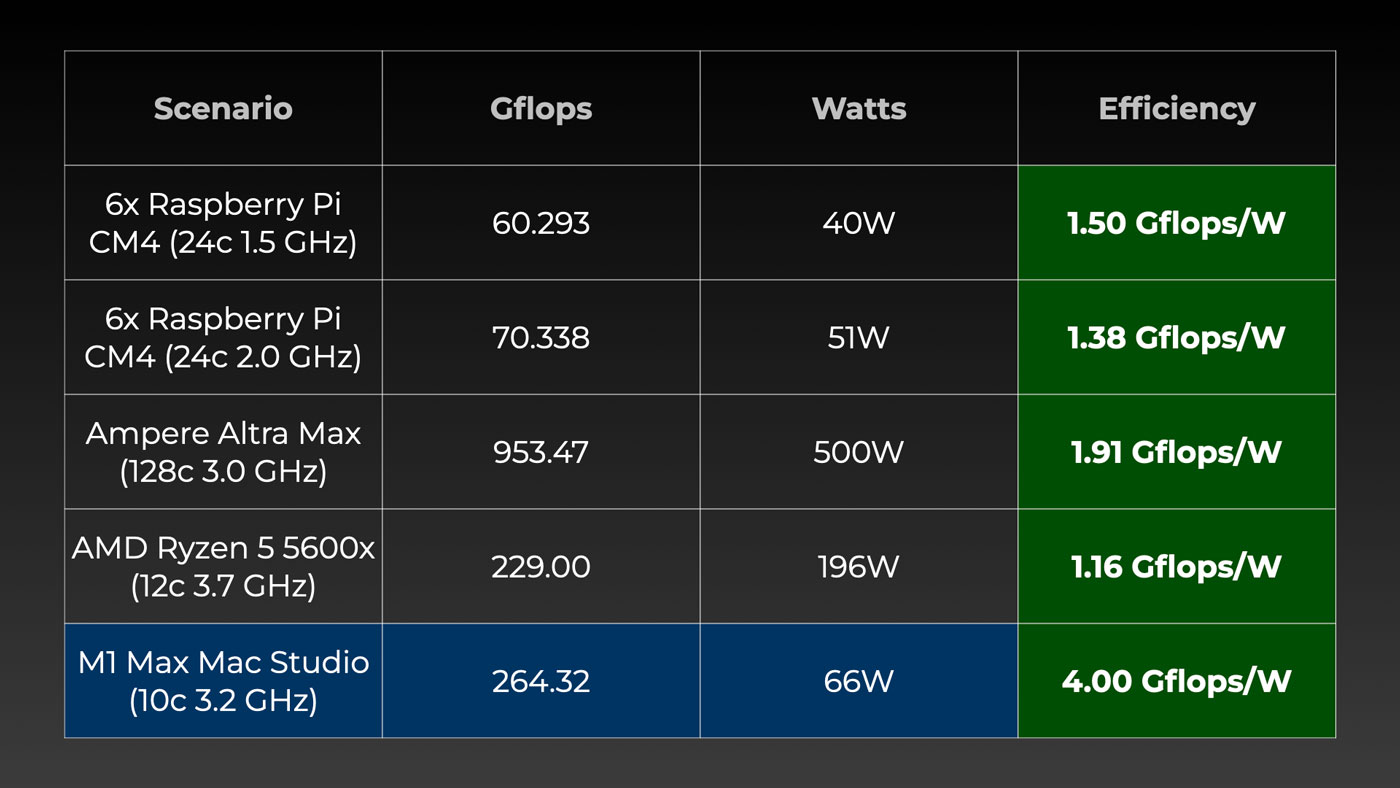
Das Ampere-System bläst am Pi-Cluster und AMD-Desktop vorbei, ist aber nicht einmal halb so effizient wie das leise kleine M1 Max Mac Studio, auf dem ich diesen Beitrag schreibe!
Effizienz ist jedoch nicht alles – für jeden Anwendungsfall müssen Sie Dinge wie Lärm, Leistung und Strombedarf, Softwarekompatibilität usw. berücksichtigen.
Und wir vergleichen nicht alles auf einmal Spielfeld, entweder. Der Supermicro-Server ist unendlich erweiterungsfähiger als mein M1 Max Mac Studio, und das Ryzen-Setup, das ich getestet habe, wurde für Spiele und KI-Tests entwickelt, nicht für Ruhe oder Energieeffizienz.
Fazit
Wie ich am Anfang dieses Beitrags sagte, bietet dir das Leben manchmal interessante Möglichkeiten. In meinem Fall hatte ich das Glück, ein wenig Zeit mit dem Ampere Altra Max zu verbringen. Jetzt habe ich einen Bezugspunkt für „die schnellste ARM-CPU, die man heute kaufen kann“. Das ist ein hilfreicher Bezugspunkt, da ich die meiste Zeit meines Tages damit verbringe, mit winzigen ARM-Systemen herumzuspielen, die weniger als 1/100 so leistungsfähig sind!
Diese Gelegenheit war auch der letzte Anstoß zur Abstraktion meines Clusters HPL-Benchmarking-Tool in ein eigenes Projekt. Hoffentlich können mehr Menschen das ohrenbetäubende Heulen von Serverfans erleben, wenn ihre eigenen Server und Cluster versuchen, sich auf dem Ampere Altra Max zu platzieren.