Hay muchos algoritmos de clasificación que se pueden usar para clasificar conjuntos de datos. Normalmente, estos datos se presentan en una lista o matriz. De estos algoritmos, el algoritmo de clasificación por selección es uno de los más simples de entender e implementar. En este artículo, explicaremos la teoría detrás de la ordenación por selección, cómo se implementa y las mejores prácticas para usar el algoritmo.
¿Qué es la ordenación por selección?
La ordenación por selección es un algoritmo de clasificación basado en la comparación. Funciona dividiendo la matriz en dos partes: ordenada y no ordenada. Se selecciona el elemento con el valor más pequeño y se coloca en el índice 0 del subarreglo ordenado. El elemento más grande también se puede seleccionar primero, dependiendo de si desea que su lista esté en orden ascendente o descendente. Este es un proceso iterativo, lo que significa que el método se repite hasta que todos los elementos se colocan en la matriz ordenada en sus posiciones correctas. Como puede esperar, con cada iteración, el tamaño del subarreglo ordenado aumenta en un elemento, mientras que el tamaño del arreglo no ordenado se reduce en un elemento.
 Puede implementar la ordenación por selección con una variedad de lenguajes de programación, incluidos C, C++, C#, PHP, Java, Javascript y Pitón.
Puede implementar la ordenación por selección con una variedad de lenguajes de programación, incluidos C, C++, C#, PHP, Java, Javascript y Pitón.
El algoritmo detrás de la ordenación por selección
El algoritmo detrás de la ordenación por selección es bastante simple y sigue estos pasos:
 El elemento mínimo en la matriz no ordenada se encuentra y se intercambia con el primer elemento, en el índice 0. La matriz no ordenada es entonces atravesado para encontrar el nuevo elemento mínimo. Si se encuentra que algún elemento es más pequeño que el elemento en el índice 0, los elementos se intercambian. Se encuentra el siguiente elemento mínimo en la matriz sin clasificar y se agrega al subarreglo ordenado, siguiendo la restricción anterior.Este proceso se repite hasta que se ordena toda la matriz.
El elemento mínimo en la matriz no ordenada se encuentra y se intercambia con el primer elemento, en el índice 0. La matriz no ordenada es entonces atravesado para encontrar el nuevo elemento mínimo. Si se encuentra que algún elemento es más pequeño que el elemento en el índice 0, los elementos se intercambian. Se encuentra el siguiente elemento mínimo en la matriz sin clasificar y se agrega al subarreglo ordenado, siguiendo la restricción anterior.Este proceso se repite hasta que se ordena toda la matriz.
Funcionamiento de la ordenación por selección
Ahora que hemos cubierto cómo funciona la ordenación por selección, es hora de ilustrar esto con un ejemplo.
Si consideramos la matriz [72, 61, 59, 47, 21]:
El primer paso, o iteración, del proceso consiste en recorrer toda la matriz desde el índice 0 hasta el índice 4 (recuerde que el primer índice se establece en 0, no en 1).
El elemento mínimo encontrado es 21, por lo que se intercambia con el primer elemento, 72. Esto se ilustra a continuación.
[21, 61, 59, 47, 72]
donde verde=elemento ordenado
Para el segundo paso, encontramos que 47 es el segundo valor más pequeño. Luego se intercambia con 61.
[21, 47, 59, 61, 72]
El tercer paso detecta que 59 es el tercer elemento, que ya está en posición. Por lo tanto, no ocurre ningún intercambio.
[21, 47, 59, 61, 72]
El cuarto paso encuentra que 61 es el cuarto elemento que, nuevamente, ya está en su lugar.
[21, 47, 59, 61, 72]
El quinto y último paso da como resultado casi lo mismo. 72 es el quinto elemento más pequeño, o el más grande, y está en la posición correcta. Ahora, la matriz está completamente ordenada en orden ascendente.
[21, 47, 59, 61, 72]
Implementación de ordenación por selección
Podemos implementar clasificación de selección con una variedad de lenguajes de programación, incluidos los más comunes: C, C ++, C #, PHP, Java, Javascript y Python. Para ilustración, vamos a usar Python. El código usado con Python es el siguiente:
def SSort(arr, tamaño): for step in range(size): min_idx=step for i in range(step + 1, size): if arr[i] arr [min_idx]: min_idx=i (arr[paso], arr[min_idx])=(arr[min_idx], arr[paso]) datos=[-7, 39, 0, 14, 7] tamaño=len(datos) SSort(data, size) print(‘Ascending Sorted Array:’) print(data)
Explicación del código
En esta etapa, será útil una explicación del código utilizado. En primer lugar, definimos la función”SSort”como una función de una matriz con un tamaño específico.
El ciclo”for”dicta que comenzará un ciclo que iterará en un rango de”tamaño”, lo que significa la longitud de la matriz. La variable “paso” indica que cada iteración tomará los valores 0, 1, 2… hasta tamaño-1.
La siguiente línea muestra que el valor inicial de “paso” es igual a la variable “ min_idx”. Esta es una forma de realizar un seguimiento de la posición del elemento mínimo en la matriz no ordenada.
El siguiente ciclo”for”especifica un ciclo que iterará sobre la matriz no ordenada, comenzando en”paso + 1″. Esto se debe a que el elemento”paso”ya está colocado en la matriz ordenada. La variable”i”en cada iteración será equivalente a paso + 1, paso + 2 y así sucesivamente hasta el tamaño – 1.
La declaración”si”que verifica si el elemento actual en”i”es menor que el elemento mínimo actual. Si se determina que este es el caso, el elemento mínimo se actualiza para reflejarlo.
Por último, esta línea bastante complicada tiene un significado simple. Una vez que el bucle anterior ha terminado, el elemento mínimo sin clasificar se intercambia con el primer elemento de la matriz sin clasificar. Esto efectivamente agrega el elemento al final de la matriz ordenada.
El código en la parte inferior simplemente dicta la matriz con la que estamos trabajando, de longitud”tamaño”, y llama a la ordenación por selección para trabajar en esto. formación. Luego, la salida se imprime con el título”Arreglo ordenado ascendente”.
Siempre que use Python, es fundamental que use la sangría correcta para designar las operaciones separadas. De lo contrario, recibirá un mensaje de error y el cálculo no se ejecutará.
Cómo se ve el código
Vea la captura de pantalla a continuación para ver cómo se ve este código cuando se implementa en Python.
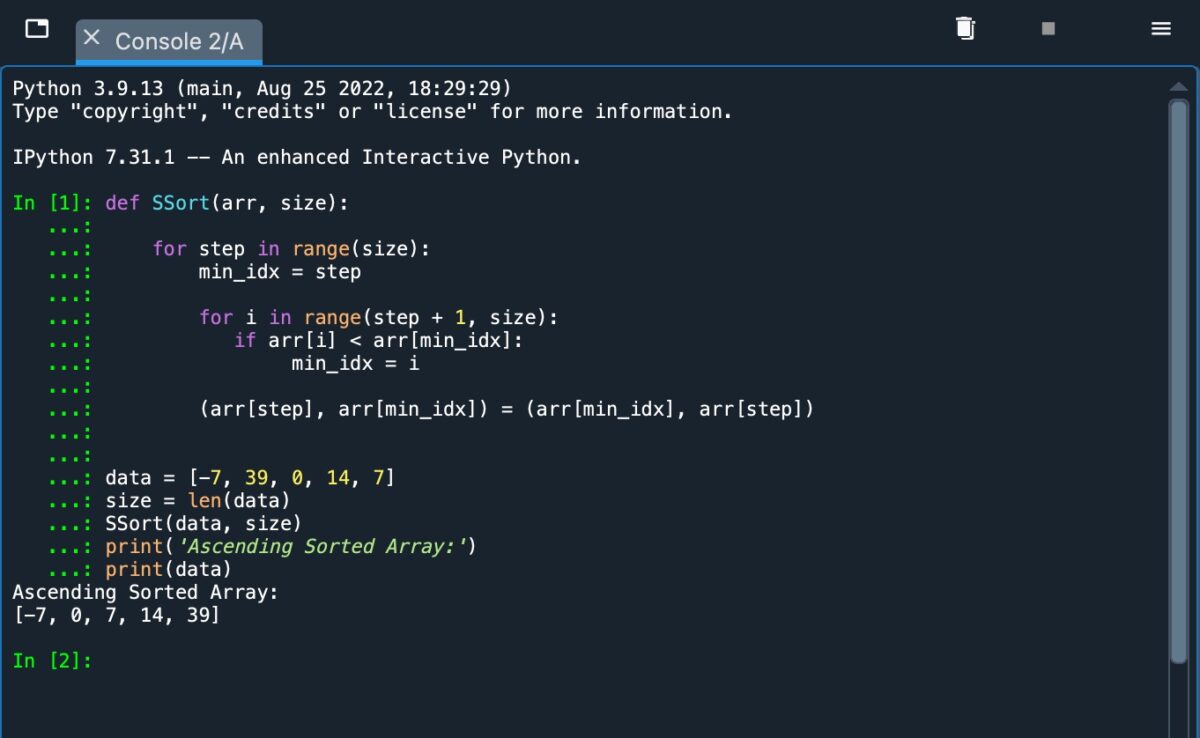 Al usar Python, debe usar la sangría correcta para designar las operaciones separadas.
Al usar Python, debe usar la sangría correcta para designar las operaciones separadas.
©”TNGD”.com
Mejores y peores casos de uso de ordenación por inserción
Si bien la ordenación por inserción es útil para muchos propósitos, como cualquier algoritmo, tiene sus mejores y peores casos. Esto se debe principalmente a la complejidad de tiempo y espacio.
Complejidad de tiempo con clasificación por inserción
La complejidad de tiempo en cada caso se puede describir en la siguiente tabla:
Me gusta con cualquier algoritmo, la ordenación por selección tiene su propia complejidad de tiempo y espacio. Esto básicamente se refiere a cómo cambia la complejidad o la velocidad de ejecución en una variedad de casos. La complejidad del tiempo se puede resumir en la siguiente tabla:
El mejor de los casos se refiere a cuándo se ordena la matriz, el caso promedio se refiere a cuando la matriz está desordenada, y el peor de los casos se refiere a cuando la matriz está en orden ascendente o descendente y desea el orden opuesto. En otras palabras, se refieren a cuántas iteraciones se necesitarán para completar el proceso, y en el peor de los casos se requiere el máximo número de iteraciones.
Para este caso, la complejidad de tiempo es idéntica para la ordenación por selección en todos los casos. caso. Esto se debe a que el algoritmo siempre realiza la misma cantidad de comparaciones e intercambios, sin importar qué tan ordenada esté la matriz. Por lo tanto, la complejidad es O(n2), también conocida como tiempo cuadrático. Esta es una de las principales razones por las que el algoritmo no es muy eficiente en lo que respecta a los algoritmos de clasificación, pero también significa que la eficiencia no depende de la distribución de la entrada.
Complejidad espacial con clasificación por selección
La complejidad del espacio se refiere a cuánta memoria se requiere para los cálculos. En el caso del ordenamiento por selección, esto es igual a O(1). Esto significa que se requiere una cantidad constante de memoria, independientemente del tamaño de entrada. La única variable temporal que se almacena es”min_idx”, que no cambia al aumentar el tamaño de entrada.
Conclusión
La ordenación por selección es un algoritmo relativamente simple pero bastante ineficiente para ordenar elementos en una entrada dada. Es principalmente apropiado para conjuntos de datos muy pequeños y se puede implementar con una variedad de lenguajes de programación. La ordenación por selección funciona dividiendo la matriz en dos subarreglos, ordenados y no ordenados. Luego, el proceso atraviesa una matriz para encontrar el elemento mínimo y mueve este elemento al índice 0. El proceso se repite, encontrando el segundo y tercer elemento más pequeño y así sucesivamente y cambiándolos a sus posiciones de índice correctas. Esto continúa hasta que se ordena toda la matriz.
A continuación…
Explicación del algoritmo de clasificación de selección, con ejemplos Preguntas frecuentes
Qué Qué es la ordenación por selección?
La ordenación por selección es un algoritmo de ordenación simple que ordena una matriz de elementos en orden ascendente o descendente. Lo hace recorriendo la matriz para encontrar el elemento mínimo y lo intercambia con el elemento en el índice 0, en un subarreglo ordenado. El subarreglo sin clasificar se recorre nuevamente y se encuentra el elemento mínimo y se cambia a su posición correcta. El algoritmo itera este proceso hasta que se ordena toda la matriz. La ordenación por selección es un algoritmo de ordenación simple que funciona encontrando repetidamente el elemento mínimo de una parte no ordenada de la matriz y colocándolo al comienzo de la parte ordenada de la matriz. El algoritmo mantiene dos subarreglos en un arreglo dado.
¿Cuáles son las ventajas del ordenamiento por selección?
El ordenamiento por selección es un algoritmo muy simple de entender e implementar , y es suficiente para conjuntos de datos muy pequeños.
¿Cuáles son los inconvenientes del ordenamiento por selección?
Debido a que no es muy eficiente, el ordenamiento por selección es inadecuado en tratar con grandes conjuntos de datos. Su eficiencia no depende de la distribución de entrada, pero esto también significa que es ineficiente en todos los casos, sin importar qué tan ordenada esté la matriz inicial. Tampoco es un algoritmo estable, lo que significa que es posible que no se conserve el orden relativo de elementos iguales. En general, existen algoritmos de ordenación superiores para la mayoría de los casos, que pueden adaptarse mejor a la entrada en cuestión.
¿Qué situaciones son mejores para usar la ordenación por selección?
La ordenación por selección se usa mejor cuando el tamaño de entrada es pequeño y desea una solución simple y relativamente eficiente. Dado que la complejidad del espacio es O(1), la ordenación por selección tiene ventajas si el uso de la memoria es algo que debe vigilar. Debido a que siempre realiza la misma cantidad de iteraciones, puede funcionar mejor que otros algoritmos al ordenar una matriz que ya está parcialmente ordenada, ya que tomar la misma cantidad de tiempo es mejor que tomar más tiempo. Si no necesita un algoritmo de ordenación estable, la ordenación por selección es una opción viable.
¿Cuál es la complejidad temporal de la ordenación por selección?
El tiempo la complejidad del ordenamiento por selección es cuadrática, representada como O(n2).
¿Cuál es la complejidad del espacio del ordenamiento por selección?
La complejidad del espacio es O( 1). Esto significa que se usa una cantidad constante de memoria para cada iteración, ya que solo se necesita almacenar una variable temporal. Si bien el algoritmo puede ser ineficiente, la complejidad del espacio significa que tiene ventajas en situaciones en las que el uso de la memoria está limitado.
¿Cuáles son algunas alternativas al ordenamiento por selección?
Muchos otros algoritmos de clasificación serán más eficientes en la mayoría de los casos de uso. Estos incluyen la ordenación por combinación, la ordenación rápida y la ordenación en montón. Estos algoritmos tienden a ser más adaptables y tienen una complejidad de tiempo mucho mejor. De estas alternativas, la ordenación por fusión es el único algoritmo estable, por lo que es viable cuando se necesita conservar el orden relativo de elementos iguales.
¿La ordenación por selección es un algoritmo estable?
No, no es un algoritmo estable. Esto significa que, al ordenar una matriz, es posible que los elementos de igual valor no se conserven en su orden original después de que se produzca el intercambio.