I Large Language Models (LLM) come GPT3, ChatGPT e BARD sono di gran moda oggi. Tutti hanno un’opinione su come questi strumenti siano positivi o negativi per la società e cosa significhino per il futuro dell’IA. Google ha ricevuto molte critiche per il suo nuovo modello BARD che ha sbagliato (leggermente) una domanda complessa. Alla domanda”Quali nuove scoperte dal telescopio spaziale James Webb posso raccontare a mio figlio di 9 anni?”– il chatbot ha fornito tre risposte, di cui 2 giuste e 1 sbagliata. Quella sbagliata era che la prima immagine di”esopianeta”fosse stata scattata da JWST, il che non era corretto. Quindi, in sostanza, il modello aveva un fatto errato memorizzato nella sua base di conoscenza. Affinché i modelli di linguaggi di grandi dimensioni siano efficaci, abbiamo bisogno di un modo per mantenere aggiornati questi fatti o aumentare i fatti con nuove conoscenze.
Osserviamo prima come i fatti vengono archiviati all’interno del modello di linguaggi di grandi dimensioni (LLM). I modelli di linguaggio di grandi dimensioni non memorizzano informazioni e fatti in senso tradizionale come database o file. Invece, sono stati addestrati su grandi quantità di dati di testo e hanno appreso schemi e relazioni in quei dati. Ciò consente loro di generare risposte simili a quelle umane alle domande, ma non dispongono di una posizione di archiviazione specifica per le informazioni apprese. Quando si risponde a una domanda, il modello utilizza l’addestramento per generare una risposta basata sull’input che riceve. Le informazioni e le conoscenze di cui dispone un modello linguistico sono il risultato dei modelli che ha appreso nei dati su cui è stato addestrato, non il risultato della loro memorizzazione esplicita nella memoria del modello. L’architettura Transformers su cui si basa la maggior parte dei moderni LLM ha una codifica interna dei fatti che viene utilizzata per rispondere alla domanda posta nel prompt.
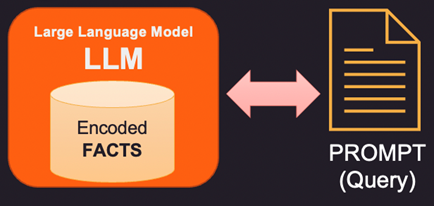
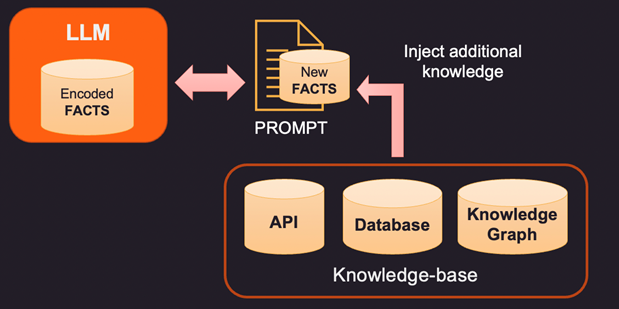
Quindi, se i fatti all’interno della memoria interna del LLM sono errati o obsoleti, è necessario fornire nuove informazioni tramite un prompt. Prompt è il testo inviato a LLM con la query e le prove a supporto che possono essere alcuni fatti nuovi o corretti. Ecco 3 modi per affrontare questo problema.
1. Un modo per correggere i fatti codificati di un LLM è fornire nuovi fatti rilevanti per il contesto utilizzando una base di conoscenza esterna. Questa base di conoscenza può essere costituita da chiamate API per ottenere informazioni rilevanti o una ricerca su un database SQL, No-SQL o Vector. Una conoscenza più avanzata può essere estratta da un grafico della conoscenza che memorizza le entità di dati e le relazioni tra di esse. A seconda delle informazioni richieste dall’utente, le informazioni contestuali pertinenti possono essere recuperate e fornite come fatti aggiuntivi al LLM. Questi fatti possono anche essere formattati per sembrare esempi di formazione per migliorare il processo di apprendimento. Ad esempio, puoi passare una serie di coppie di domande-risposte al modello per imparare a fornire risposte.
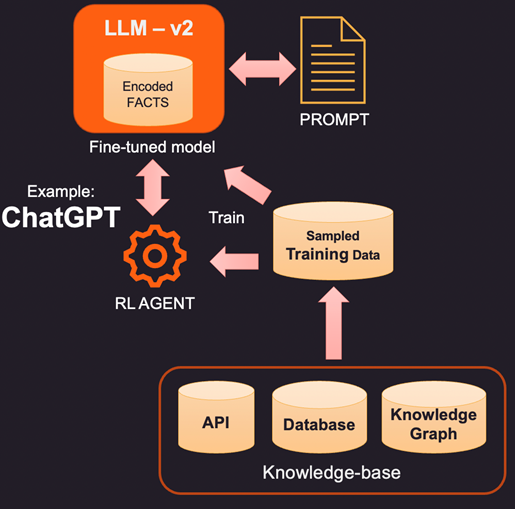
2. Un modo più innovativo (e più costoso) per aumentare l’LLM è l’effettiva messa a punto utilizzando i dati di addestramento. Quindi, invece di interrogare la base di conoscenza per fatti specifici da aggiungere, costruiamo un set di dati di addestramento campionando la base di conoscenza. Utilizzando tecniche di apprendimento supervisionato come la messa a punto, potremmo creare una nuova versione del LLM addestrata su questa conoscenza aggiuntiva. Questo processo è generalmente costoso e può costare qualche migliaio di dollari per creare e mantenere un modello ottimizzato in OpenAI. Ovviamente, il costo dovrebbe diminuire nel tempo.
3. Un’altra opzione è utilizzare metodi come Reinforcement Learning (RL) per addestrare un agente con feedback umano e apprendere una politica su come rispondere alle domande. Questo metodo è stato molto efficace nella creazione di modelli di footprint più piccoli che ottengono buoni risultati in attività specifiche. Ad esempio, il famoso ChatGPT rilasciato da OpenAI è stato addestrato su una combinazione di apprendimento supervisionato e RL con feedback umano.
In sintesi, questo è uno spazio in continua evoluzione in cui tutte le principali aziende vogliono entrare e mostrare la propria differenziazione. Presto vedremo i principali strumenti LLM nella maggior parte delle aree come la vendita al dettaglio, l’assistenza sanitaria e le banche che possono rispondere in modo umano comprendendo le sfumature del linguaggio. Questi strumenti basati su LLM integrati con i dati aziendali possono semplificare l’accesso e rendere disponibili i dati giusti alle persone giuste al momento giusto.